Foreword
The original version of this blog post was published in June 2023.
An update took place in November 2024 to reference the QAmemberta, which appears to be the new state of the art for the question answering task.
A new update was made in April 2025 to reference the modernQAmembert.
What is question answering?
Question answering (often abbreviated as QA) is an NLP task that involves providing an answer to a user's question formulated in natural language.
There are two types of question answering. The first is referred to as "QA closed-book," where the model answers a question without relying on any associated context text. This approach can be likened to the "Using your knowledge, answer the following question" exercise we encountered as students.
The performance of these types of models primarily depends on the data used for training, but we won't delve into further details on this type of QA in this article.
The second type of QA that will be of interest to us in the remainder of this blog post is "extractive QA," where the model answers a question based on an associated context text, with the answer extracted from a given text—hence the term "extractive." This is the default approach when discussing QA.
It's worth noting that for each of these two types, they can be categorized as "closed-domain" (models specialized in a specific domain, e.g., medical) or "open-domain" (models trained on various domains to be as general as possible).
From a technical perspective, the QA extractive task can be seen as binary classification. Instead of classifying at the sentence level (as in sentiment analysis, for example), it operates at the word level, determining whether the word in question is part of the expected response or not.
QA datasets with context
The most renowned QA dataset is the SQuAD (Stanford Question Answering Dataset) by Rajpurkar et al. Originally developed in English using Wikipedia articles as a source, its formatting has been widely embraced in other languages.
This dataset comes in two versions. SQuAD 1.0 by Rajpurkar et al. (2016) comprises 107,785 triplets consisting of context text, a question, and an answer. Below is an example of a line from this version of the dataset:
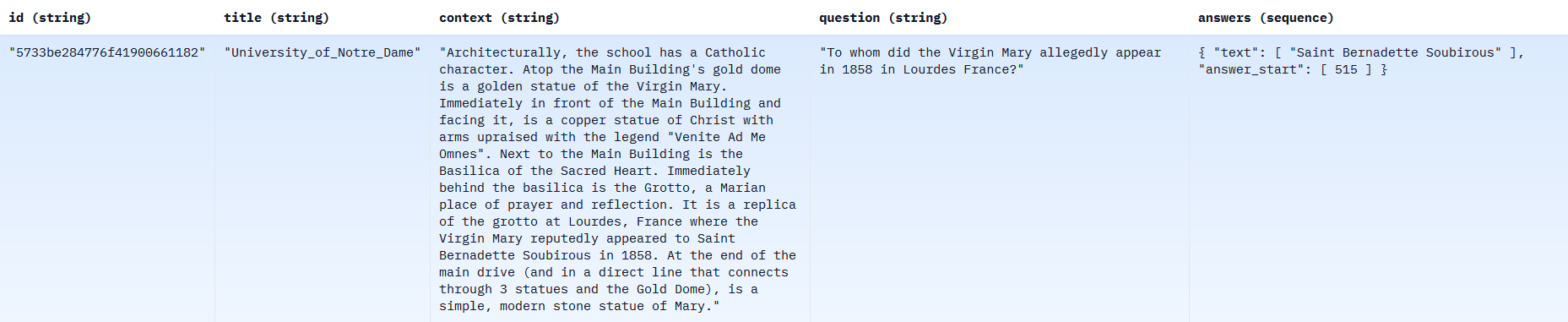
SQuAD 2.0 by Rajpurkar et al. (2018) introduces 53,775 additional triplets in which the answers are intentionally left empty. This means that the context does not contain the answer to the question asked. The purpose of this variation is to train the model not to automatically extract text from the context in every case, recognizing that sometimes a question lacks an answer, and the model should refrain from providing one. In SQuAD 2.0, approximately two-thirds of the questions have answers taken from the context, while one-third have no answers.
Below is an example of a line from this version of the dataset:

For the French language, several datasets have been created using the SQuAD methodology. These datasets include:
- FQuAD 1.0 (2020) by Illuin Technology (in particular Hoffschmidt et al. (2021), which is based on the SQuAD 1.0 methodology and contains 26,108 questions/answers based on high-quality Wikipedia articles. The data is available on the Illuin Technology website after filling in a form (only the train and dev samples are available, not the test). Version FQuAD 1.1 by the same authors contains 62,003 questions/answers, but this dataset is not open.
- FQuAD 2.0 by Heinrich et al. using SQUAD 2.0 methodology bringing 13,591 new unanswered questions. However, this dataset is not open.
- The PIAF (Pour une IA Francophone) project supported by Etalab and more specifically Keraron et al. (2020) includes more than 9,225 questions. The PIAF data are freely accessible here.
- Newsquadfr (2021) by Lincoln is a dataset of 2,520 questions. The contexts are paragraphs of articles extracted from nine French online newspapers during the year 2020/2021.
A total of 37,853 context/question/answer triplets are available natively in French.
There are also a few datasets that are translations of SQuAD into French. These include:
- French-SQuAD by Kabbadj (2018), which translates the SQuAD 1.0 dataset using Google's unofficial API. This translation is not of good quality (punctuation, nonsense phrases).
- Squad_fr by Cattan et al. (2021), which translates the SQuAD 1.0 dataset using their own translation system based on the transformer by Vaswani et al. Although of better quality than French-SQuAD, this dataset contains many errors.
- Squad_v2_french_translated by Pragnakalp Techlabs (2022), which partially translates (79,069 data out of the original 161,560) the SQuAD 2.0 dataset using Google Translate. This dataset is the best quality of the three available translations.
Which model for solving a QA task?
Any transformer model is capable of performing this task, whether it's a complete transformer (with both encoder and decoder), a transformer decoder, or a transformer encoder.
The key difference lies in how the data is presented to the model in each approach.
In practice, encoder models are the most widely used. Because they are best suited to solving classification tasks, and probably out of habit. Notably, in the case of the French language, encoder transformers were available before decoder transformers and full transformers. Furthermore, it's worth mentioning that the CamemBERT model by Martin et al. (2019) is more commonly used than FlauBERT by He et al. (2019) for the QA task, due to empirical observations: several authors have noted that the former tends to give better results than the latter on this task.
Note that in November 2024, Antoun et al. (2024) introduced CamemBERT 2.0. In this paper, they actually propose two models: a CamemBERT2 and a CamemBERTa2. These models are trained on more data than in their first version and have the advantage of being able to handle a sequence of 1024 tokens compared with 512 previously.
In April 2025, Antoun et al. (2025) introduced modernCamemBERT, a French-language version of modernBERT by <a href=“https://arxiv.org/abs/2504.08716”>Warner, Chaffin, Clavié et al. et al. (2025)</a> that manages a sequence of 8192 tokens.
A few models finetuned to the QA task are available in open-source. These include:
- The CamemBERT base model finetuned on FQUAD 1.0 by Illuin
- The CamemBERT model finetuned on the combination of PIAF 1.1, FQuAD 1.0 and French-SQuAD by Etalab
- The DistillCamemBERT base model finetuned on FQUAD 1.0 and PIAF by Crédit Mutuel
Each of these models has its limitations.
Firstly, none of them uses all the available data:
- Illuin's model uses only one dataset, i.e. 26,108 questions/answers (including 2,189 test questions/answers).
- Etalab's model uses three, i.e. around 128,090 questions/answers (including 3,188 test questions/answers), including the French-SQuAD, which is of poor quality, and PIAF version 1.1, containing 7,570 questions/answers, instead of version 1.2, containing 9,225 questions/answers.
- Crédit Mutuel's uses only two sets of data, i.e. 27,754 questions/answers (including 3,188 test questions/answers).
Secondly, all the data used in these models is based solely on the SQuAD 1.0 methodology, which mandates that the answer to the question must be present within the context text.
Thirdly, the Crédit Mutuel model is a distilled CamemBERT. Consequently, it has fewer parameters compared to the other models, but in return achieves lower performance. If your objective is to have the smallest model possible, because you have hardware constraints for example, this model is certainly the best suited to your needs. However, if your aim is to achieve the best possible performance, it is advisable to avoid this model.
Keeping these limitations in consideration, we have created our own model at CATIE, known as QAmembert. QAmembert leverages all the high-quality open-source data, incorporates new data to adhere to the SQuAD 2.0 methodology, and provides four models freely available in open-source:
- https://hf.co/CATIE-AQ/QAmembert: 110M parameters and context size of 512 tokens, finetuned model from almanach/camembert-base,
- https://hf.co/CATIE-AQ/QAmembert2: 112M, 1024 tokens, finetuned model from almanach/camembertv2-base,
- https://hf.co/CATIE-AQ/QAmemberta: 112M, 1024 tokens, finetuned model from almanach/camembertav2-base,
- https://hf.co/CATIE-AQ/QAmembert-large: 336M, 512 tokens, finetuned model from almanach/camembert-large.
- https://hf.co/CATIE-AQ/ModernQAmembert : 136M, 8192 tokens, finetuned model from almanach/moderncamembert-cv2-base.
In particular, we used :
| Dataset | Format | Train split | Dev split | Test split |
| PIAF 1.2 | SQuAD 1.0 | 9,225 Q & A | X | X |
| FQuAD 1.0 | SQuAD 1.0 | 20,731 Q & A | 3,188 Q & A (not used for training because used as a test dataset) | 2,189 Q & A (not used in our work because not freely available) |
| lincoln/newsquadfr | SQuAD 1.0 | 1,650 Q & A | 455 Q & A (not used in our work) | 415 Q & A (not used in our work) |
| pragnakalp/squad_v2_french_translated | SQuAD 2.0 | 79,069 Q & A | X | X |
For each of the datasets, we generated questions without answers within the associated context. To achieve this, for a given context, we removed the anticipated answer and replaced the original question with a random one, which could be sourced from the original dataset or any of the other three datasets. We ensured that the new question was distinct from the previous one.
We thus end up with an augmented dataset whose answer may or may not be present in the context, for a total of 227,726 (221,350 for training, 6,376 for testing) question/answer/context triples. These new unanswered questions have been indexed in a dataset called FrenchQA, which is now available in open-source.
The idea of using a question that has previously been asked to substitute an original question, rather than introducing an entirely new question, is to enhance the model's robustness. Indeed, the fact that the same question has several possible answers (in this case, an answer and a "non-answer") should, according to our hypothesis, enable us to have a model that doesn't specialize in providing a specific answer to a particular question, but remains generalist. In other words, it should focus on the phenomenon of seeking an answer rather than delivering an absolute answer.
Metrics and evaluation
How do the models perform? Let's start by describing the metrics on which QA models are evaluated.
Metrics
There are some differences between the metrics in SQuAD 1.0 and SQuAD 2.0.
For SQuAD 1.0, the exact match and F1 score are calculated. The exact match is determined by the strict correspondence of the predicted and correct response characters. For correctly predicted answers, the exact match will be 1. And even if only one character is different, the exact match is set to 0.
The F1 score, on the other hand, is the harmonic mean between precision and recall. It is calculated for each word in the predicted sequence in relation to the correct answer.
For SQuAD 2.0, in addition to calculating the exact-match and F1 score, it is possible to obtain F1 and exact-match details for questions with an answer, as well as F1 and exact-match details for questions without an answer.
Evaluation
From an implementation point of view, the best way to calculate the above metrics is to use the python package evaluate by Hugging Face.
Performance results for the various models considered are available in the table below.
| Model | Parameters | Context | Exact_match | F1 | Answer_f1 | NoAnswer_f1 |
|---|---|---|---|---|---|---|
| etalab/camembert-base-squadFR-fquad-piaf | 110M | 512 tokens | 39.30 | 51.55 | 79.54 | 23.58 |
| QAmembert | 110M | 512 tokens | 77.14 | 86.88 | 75.66 | 98.11 |
| QAmembert2 | 112M | 1024 tokens | 76.47 | 88.25 | 78.66 | 97.84 |
| ModernQAmembert | 136M | 8192 tokens | 76.73 | 88.85 | 79.45 | 98.24 |
| QAmembert-large | 336M | 512 tokens | 77.14 | 88.74 | 78.83 | 98.65 |
| QAmemberta | 111M | 1024 tokens | 78.18 | 89.53 | 81.40 | 97.64 |
Looking at the “Answer_f1” column, Etalab's model appears to be competitive on texts where the answer to the question is indeed in the text provided (it does better than QAmemBERT-large, for example). However, the fact that it doesn't handle texts where the answer to the question is not in the text provided is a drawback.
In all cases, whether in terms of metrics, number of parameters or context size, QAmemBERTa achieves the best results.
We therefore invite the reader to choose this model.
Examples of use
When the answer is present in the context:
from transformers import pipeline
qa = pipeline('question-answering', model='CATIE-AQ/QAmembert', tokenizer='CATIE-AQ/QAmembert')
result = qa({
'question': "Combien de personnes utilisent le français tous les jours ?",
'context': "Le français est une langue indo-européenne de la famille des langues romanes dont les locuteurs sont appelés francophones. Elle est parfois surnommée la langue de Molière. Le français est parlé, en 2023, sur tous les continents par environ 321 millions de personnes : 235 millions l'emploient quotidiennement et 90 millions en sont des locuteurs natifs. En 2018, 80 millions d'élèves et étudiants s'instruisent en français dans le monde. Selon l'Organisation internationale de la francophonie (OIF), il pourrait y avoir 700 millions de francophones sur Terre en 2050."
})
if result['score'] < 0.01:
print("La réponse n'est pas dans le contexte fourni.")
else :
print(result['answer'])
235 millions
# details
result
{'score': 0.9945194721221924,
'start': 269,
'end': 281,
'answer': '235 millions'}
When the answer is not contained in the context:
from transformers import pipeline
qa = pipeline('question-answering', model='CATIE-AQ/QAmembert', tokenizer='CATIE-AQ/QAmembert')
result = qa({
'question': "Quel est le meilleur vin du monde ?",
'context': "La tour Eiffel est une tour de fer puddlé de 330 m de hauteur (avec antennes) située à Paris, à l’extrémité nord-ouest du parc du Champ-de-Mars en bordure de la Seine dans le 7e arrondissement. Son adresse officielle est 5, avenue Anatole-France.
Construite en deux ans par Gustave Eiffel et ses collaborateurs pour l'Exposition universelle de Paris de 1889, célébrant le centenaire de la Révolution française, et initialement nommée « tour de 300 mètres », elle est devenue le symbole de la capitale française et un site touristique de premier plan : il s’agit du quatrième site culturel français payant le plus visité en 2016, avec 5,9 millions de visiteurs. Depuis son ouverture au public, elle a accueilli plus de 300 millions de visiteurs."
})
if result['score'] < 0.01:
print("La réponse n'est pas dans le contexte fourni.")
else :
print(result['answer'])
La réponse n'est pas dans le contexte fourni.
# details
result
{'score': 3.619904940035945e-13,
'start': 734,
'end': 744,
'answer': 'visiteurs.'}
If you’d like to test the model more directly, a demonstrator has been created and is hosted as a Space on Hugging Face. It is available here or below:
Possible improvements
To conclude, let's outline some potential enhancements for this work.
Firstly, it would be valuable to vary the number of unanswered questions. In order to simplify the process, we have doubled the number of questions in our unanswered data creation process. This might be impacting the performance, as we can see that the F1 score for unanswered data is at least 10 points higher than that for answered questions. In order to balance these two F1 scores, we might consider reducing the number of unanswered questions. The SQuAD 2.0 dataset uses a 66% (answered)/33% (unanswered) split, as opposed to our 50%/50% split.
Secondly, we need to balance the different types of questions (who? what? where? why? how? when? etc.). The objective is to create a model that performs well regardless of the type of questions used. At present, the distribution is as follows:
| Type of question | Frequency in percent |
| What (que) | 55.12 |
| Who (qui) | 16.24 |
| How much (combien) | 7.56 |
| When (quand) | 6.85 |
| Where (où) | 3.98 |
| How (comment) | 3.76 |
| What (quoi) | 2.94 |
| Why (pourquoi) | 1.41 |
| Other | 2.14 |
In a similar vein, we could increase the number of questions containing a negation, e.g. "What was the name of Chopin's first music teacher who was not an amateur musician?", which currently accounts for only 3.07% of questions.
This would, however, require investment in annotation in new data, although the first point mentioned could help in rebalancing. An alternative might be to scrape open-source online data, such as patent annals and, more generally, exercises asking students to answer a question by quoting an extract from a text.
Thirdly, it is worth exploring the integration of a portion of unanswered data from corpora other than those used here. The logic we have applied is to take questions from SQuAD 1.0-type corpora so that the same question is sometimes an answer and other times not, so that the model doesn't learn a given answer to a given question and thus overlearn.
The idea of introducing unanswered questions (along with new associated contexts) that are not part of the SQuAD 1.0 datasets is to increase the variety of questions encountered by the model. There are a few datasets available in French, including:
- Mkqa by Longpre et al. (2021) is a multilingual dataset containing 10,000 questions in French. An interesting piece of information that is specified in this dataset is that the type of question (who? what? when? etc.) must be specified by the user.
- X-CSR by Lin et al. (2021) contains two subsets. For QA, only the X-CSQA subset containing 2,074 questions and answers is relevant.
This means that 12,074 questions in French are available in the SQuAD 2.0 methodology.
Finally, it would be advisable to generate a new test dataset for research purposes, instead of relying on the FQuAD 1.0 dev dataset, which is currently in common use. The FQuAD 1.0 dev dataset is subject to a restrictive license that prevents it from being shared in the SQuAD 2.0 format.
Conclusion
We introduce the QAmembert model in four versions, which are freely accessible on Hugging Face.
These models are the first in French and in open-source to adopt the SQuAD 2.0 methodology.
We remain open to the possibility of future developments, particularly in addressing the balance of question types.
Citations
Models
@misc {qamemberta2024,
author = { {BOURDOIS, Loïck} },
organization = { {Centre Aquitain des Technologies de l'Information et Electroniques} },
title = { QAmemberta (Revision 976a70b) },
year = 2024,
url = { https://huggingface.co/CATIE-AQ/QAmemberta },
doi = { 10.57967/hf/3639 },
publisher = { Hugging Face }
}
@misc {qamembert2023,
author = { {ALBAR, Boris and BEDU, Pierre and BOURDOIS, Loïck} },
organization = { {Centre Aquitain des Technologies de l'Information et Electroniques} },
title = { QAmembert (Revision 9685bc3) },
year = 2023,
url = { https://huggingface.co/CATIE-AQ/QAmembert},
doi = { 10.57967/hf/0821 },
publisher = { Hugging Face }
}
Datasets
@misc {frenchQA2023,
author = { {ALBAR, Boris and BEDU, Pierre and BOURDOIS, Loïck} },
organization = { {Centre Aquitain des Technologies de l'Information et Electroniques} },
title = { frenchQA (Revision 6249cd5) },
year = 2023,
url = { https://huggingface.co/CATIE-AQ/frenchQA },
doi = { 10.57967/hf/0862 },
publisher = { Hugging Face }
}
References
- SQuAD: 100,000+ Questions for Machine Comprehension of Text by Rajpurkar et al. (2016)
- Know What You Don't Know: Unanswerable Questions for SQuAD by Rajpurkar et al. (2018)
- FQuAD: French Question Answering Dataset by Hoffschmidt et al. (2020)
- FQuAD2.0: French Question Answering and knowing that you know nothing by Heinrich et al. (2021)
- Project PIAF: Building a Native French Question-Answering Dataset by Keranon et al. (2020)
- Newsquadfr by Lincoln (2021)
- CamemBERT: a Tasty French Language Model de Martin et al. (2019)
- FlauBERT: Unsupervised Language Model Pre-training for French de He et al. (2019
- CamemBERT 2.0: A Smarter French Language Model Aged to Perfection by Antoun et al. (2024)
- ModernBERT or DeBERTaV3? Examining Architecture and Data Influence on Transformer Encoder Models Performance by Antoun et al. (2025)
- Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference by Warner, Chaffin, Clavié et al. (2024)
- Something new in French Text Mining and Information Extraction (Universal Chatbot): Largest Q&A French training dataset (110 000+) by Kabbadj (2018)
- On the Usability of Transformers-based models for a French Question-Answering task by Cattan et al. (2021)
- SQuAD v2 French Translated by Pragnakalp Techlabs (2022)
- MKQA: A Linguistically Diverse Benchmark for Multilingual Open Domain Question Answering by Longpre et al. (2021)
- Common Sense Beyond English: Evaluating and Improving Multilingual Language Models for Commonsense Reasoning by Lin et al. (2021)