Avant-propos
La version initiale de cet article de blog a été mise en ligne en juin 2023.
Une actualisation a eu lieu en novembre 2024 pour référencer le QAmemberta qui apparait comme être le nouvel état de l’art pour la tâche de question answering.
Une nouvelle actualisation a eu lieu en avril 2025 pour référencer le modernQAmembert.
Qu’est-ce que le question answering ?
Le question answering (souvent abrégé en QA) est une tâche de NLP consistant à apporter une réponse à une question de l’utilisateur formulée en langage naturel.
Il existe deux types de question answering. Le premier est appelé « QA closed-book», c’est-à-dire que le modèle répond à une question sans se baser sur un texte de contexte associé. On peut voir cette approche comme l’exercice « À l’aide de vos connaissances, répondez à la question suivante » que l’on a eue à traiter lorsque l’on était élève.
Les performances de ces types de modèles dépendent principalement des données qui ont servi lors de l’entraînement. Nous ne traiterons pas plus en détails ce type de QA dans cet article.
Le second type de QA qui va nous intéresser dans la suite de ce billet de blog est l’ « extractive QA », c’est-à-dire que le modèle répond à une question en se basant sur un texte de contexte associé : on extrait la réponse dans un texte donné, d’où le terme « extractive ». C’est l’approche considérée par défaut lorsque l’on parle de QA.
À noter que pour chacun des deux types, il est possible de les qualifier de « closed-domain » (modèle spécialisé sur un domaine particulier, par exemple le médical) ou d’« open-domain » (modèle entraîné sur plusieurs domaines différents pour le rendre le plus généraliste possible).
D’un point de vue technique, la tâche d’extractive QA peut être considérée comme de la classification binaire où au lieu de classifier au niveau de la phrase entière (pour de l’analyse de sentiment par exemple), l’on classifie au niveau du mot en disant si oui ou non le mot considéré fait partie de la réponse attendue.
Jeux de données de QA avec contexte
Le jeu de données le plus connu et faisant référence en QA, est le jeu de données SQuAD (Stanford Question Answering Dataset) de Rajpurkar et al. Créé pour l’anglais à partir d’articles de Wikipedia, les autres langues ont généralement adopté son formatage.
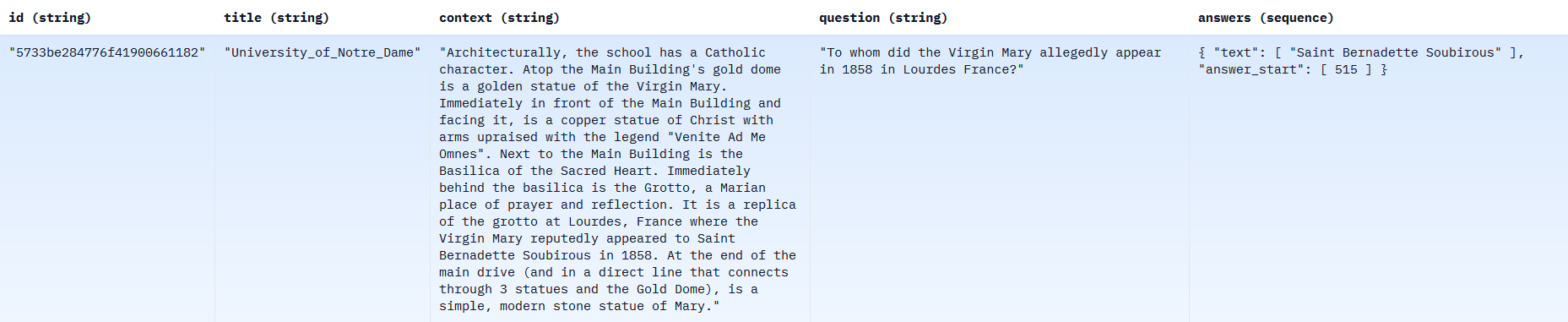
Il faut préciser qu’il existe deux versions de ce jeu de données. SQuAD 1.0 de Rajpurkar et al. (2016) contient 107 785 triplets texte de contexte, question, réponse. Ci-dessous un exemple d’une ligne de cette version du jeu de données :
SQuAD 2.0 de Rajpurkar et al. (2018) contient 53 775 triplets additionnels où les réponses sont vides, c’est-à-dire que le contexte ne contient pas la réponse à la question posée. Cela permet d’entraîner le modèle à ne pas ressortir systématiquement un bout du texte de contexte et que parfois, une question n’a pas de réponse et qu’il faut donc s’abstenir. Dans cette version, deux tiers des questions possèdent des réponses issues du contexte et un tiers des questions ne possède pas de réponse.
Ci-dessous un exemple d’une ligne de cette version du jeu de données :

En ce qui concerne le français, des jeux de données ont été créés suivant la méthodologie de SQuAD. On peut citer :
- FQuAD 1.0 (2020) de l’entreprise Illuin Technology (plus particulièrement Hoffschmidt et al.) qui se base sur la méthodologie de SQuAD v1. Elle contient 26 108 questions/réponses basées sur des articles de qualité de Wikipédia. Les données sont accessibles sur le site d’Illuin Technology après avoir rempli un formulaire (seulement les échantillons train et dev sont accessibles, pas le test). La version FQuAD 1.1 par les mêmes auteurs contient 62 003 questions/réponses mais ce jeu de données n’est pas ouvert.
- FQuAD 2.0 de Heinrich et al. (2021) utilisant la méthodologie de SQUAD 2.0 apportant 13 591 nouvelles questions sans réponse. Cependant, ce jeu de données n’est pas ouvert.
- Le projet PIAF (Pour une IA Francophone), porté par Etalab et plus particulièrement Keraron et al. (2020) comporte plus de 9 225 questions dans sa version finale (la version 1.2). Les données de PIAF sont accessibles librement ici.
- Newsquadfr (2021) de Lincoln est un jeu de données de 2 520 questions. Les contextes sont des paragraphes d'articles extraits de neuf journaux français en ligne au cours de l'année 2020/2021.
Ce sont donc 37 853 triplets contextes/questions/réponses qui sont disponibles nativement en français.
Il existe également quelques jeux de données étant des traductions de SQuAD vers le français. À savoir :
- French-SQuAD de Kabbadj (2018) qui traduit le jeu de données SQuAD v1 en utilisant l’API non officielle de Google. Cette traduction n’est pas de bonne qualité.
- Squad_fr de Cattan et al. (2021) qui traduit le jeu de données SQuAD v1 en utilisant leur propre système de traduction basé sur le transformer de Vaswani et al. Bien que de meilleure qualité que French-SQuAD, ce jeu de données contient beaucoup d’erreurs.
- Squad_v2_french_translated de Pragnakalp Techlabs (2022) qui traduit partiellement (79 069 données sur les 161 560 originales) le jeu de données SQuAD v2 en utilisant Google Translate. Ce jeu de données est celui présentant la meilleure qualité parmi les trois traductions disponibles.
Quel modèle pour résoudre une tâche de QA ?
N’importe quel modèle de transformer est capable de résoudre cette tâche, que ce soit un transformer complet (encodeur et décodeur), un transformer décodeur, ou un transformer encodeur. Seule la façon dont sont fournies les données au modèle diffère entre les différentes approches.
En pratique, les modèles de type encodeur sont les plus utilisés. Du fait qu’ils sont les plus adaptés pour résoudre des tâches de classification, et probablement par habitude. En effet, dans le cas du français, les transformers encodeur ont été disponibles avant les transformers décodeur et les transformers complet. Soulignons également que le modèle CamemBERT de Martin et al. (2019) est davantage utilisé que le FlauBERT de He et al. (2019) pour la tâche de QA du fait d’observations empiriques : plusieurs auteurs ont remarqué que le premier a tendance à donner de meilleurs résultats que le second sur cette tâche.
Notons qu'en novembre 2024, Antoun et al. (2024) ont introduit le CamemBERT 2.0. Dans ce papier, ils proposent en réalité deux modèles : un CamemBERT2 et un CamemBERTa2. Ces modèles sont entraînés sur plus de données que dans leur première version et ont l'intérêt de pouvoir gérer une séquence de 1024 tokens contre 512 précédemment.
En avril 2025, Antoun et al. (2025) ont introduit le modernCamemBERT, une version en français du modernBERT de Warner, Chaffin, Clavié et al. et al. (2025) permettant de gérer une séquence de 8192 tokens.
Quelques modèles finetunés sur la tâche de QA sont disponibles en open-source. On peut lister :
- Le modèle CamemBERT base finetuné sur FQUAD 1.0 par Illuin
- Le modèle CamemBERT base finetuné sur la combinaison de PIAF 1.1, FQuAD 1.0 et French-SQuAD par Etalab
- Le modèle DistillCamemBERT base finetuné sur FQUAD 1.0 et PIAF par le Crédit Mutuel
Ces différents modèles ont chacun des limites.
Premièrement, aucun d’entre eux n’utilise la totalité des données disponibles à disposition :
- Le modèle d’Illuin n’utilise qu’un jeu de données soient 26 108 questions/réponses (dont 2 189 de test).
- Celui d’Etalab en utilise trois, soient environ 128 090 questions/réponses (dont 3 188 de test), dont le French-SQuAD qui est de mauvaise qualité et la version 1.1 de PIAF contenant 7 570 questions/réponses au lieu de la version 1.2 contenant 9 225 questions/réponses.
- Celui du Crédit Mutuel n’utilise que deux jeux de données soit 27 754 questions/réponses (dont 3 188 de test).
Deuxièmement, toutes les données utilisées dans ces modèles se basent uniquement sur la méthodologie de SQuAD 1.0 imposant que la réponse à la question se trouve dans le texte de contexte.
Troisièmement, dans le cadre du modèle du Crédit Mutuel, celui-ci est un CamemBERT distillé. Il possède moins de paramètres que les autres mais obtient, en contrepartie, des performances plus faibles. Si votre objectif est d’avoir le modèle le plus petit possible car avez des contraintes de matériel par exemple, ce modèle est certainement le plus adapté à votre besoin. Cependant, si votre objectif est d’avoir un modèle ayant les meilleures performances possibles, il sera à éviter.
Compte tenu de ces points limitants, nous avons développé notre propre modèle au CATIE : le QAmembert. Celui-ci utilise l’ensemble des données de qualité à disposition en open-source, se base sur de nouvelles données afin d’adopter la méthodologie SQuAD 2.0 et propose cinq modèles gratuitement et librement en open-source :
- https://hf.co/CATIE-AQ/QAmembert : 110M de paramètres et taille de contexte de 512 tokens, modèle finetuné à partir d'almanach/camembert-base,
- https://hf.co/CATIE-AQ/QAmembert2 : 112M, 1024 tokens, modèle finetuné à partir d'almanach/camembertv2-base,
- https://hf.co/CATIE-AQ/QAmemberta : 112M, 1024 tokens, modèle finetuné à partir d'almanach/camembertav2-base,
- https://hf.co/CATIE-AQ/QAmembert-large : 336M, 512 tokens, modèle finetuné à partir d'almanach/camembert-large.
- https://hf.co/CATIE-AQ/ModernQAmembert : 136M, 8192 tokens, modèle finetuné à partir d'almanach/moderncamembert-cv2-base.
Précisément, nous avons utilisé :
| Jeu de données | Format | Train split | Dev split | Test split |
| PIAF 1.2 | SQuAD 1.0 | 9 225 Q & A | X | X |
| FQuAD 1.0 | SQuAD 1.0 | 20 731 Q & A | 3 188 Q & A (non utilisé pour l'entraînement car servant de jeu de données de test) | 2 189 Q & A (non utilisé dans notre travail car non disponible librement) |
| lincoln/newsquadfr | SQuAD 1.0 | 1 650 Q & A | 455 Q & A (non utilisé dans notre travail) | 415 Q & A (non utilisé dans notre travail) |
| pragnakalp/squad_v2_french_translated | SQuAD 2.0 | 79 069 Q & A | X | X |
Pour chacun des jeux de données, nous avons créé des questions ne comportant pas de réponse dans le contexte associé. Pour cela, nous avons supprimé, pour un contexte donné, la réponse attendue et remplacé la question originale par une autre aléatoire (pouvant provenir du jeu de données original ou bien d’un des trois autres). Nous nous sommes assurés que la nouvelle question n’était pas la même que la précédente.
Nous nous retrouvons ainsi avec un jeu de données augmenté dont la réponse peut ou non être présente dans le contexte, pour un total de de 227 726 (221 350 pour l’entraînement, 6 376 pour le test) triplets questions/réponses/contextes.
Ces nouvelles questions sans réponse ont été répertoriées dans un jeu de données appelé FrenchQA que nous mettons à disposition en open-source.
L’idée de reprendre une question déjà posée en remplacement d’une question originale plutôt qu’une question complètement externe jamais vue, est d’essayer de rendre le modèle plus robuste. En effet, le fait qu’une même question ait plusieurs réponses possibles (en l’occurrence une réponse et une « non réponse ») doit, selon notre hypothèse, permettre d’avoir un modèle ne se spécialisant pas à répondre une réponse donnée à une question donnée et qu’il reste généraliste. C’est-à-dire qu'il se concentre sur la recherche d'une réponse plutôt que de répondre absolument.
Métriques et évaluation
Quelles sont les performances des modèles ? Pour cela décrivons d’abord les métriques sur lesquelles sont évalués les modèles de QA.
Métriques
Il existe quelques différences entre les métriques de et SQuAD 2.0.
Pour SQuAD 1.0, l’exact-match et le score F1 sont calculés. L’exact match est basé sur la correspondance stricte des caractères de la réponse prédite et de la bonne réponse. Pour les réponses correctement prédites, la correspondance exacte sera de 1. Et même si un seul caractère est différent, la correspondance exacte sera de 0.
Le score F1 est la moyenne harmonique entre la précision et le rappel. Il est calculé pour chaque mot de la séquence prédite par rapport à la réponse correcte.
Pour SQuAD 2.0, en plus de calculer l’exact-match et le score F1, il est possible d’obtenir le détail du F1 et de l’exact-match pour les questions possédant une réponse de même que le détail du F1 et de l’exact-match pour les questions ne possédant pas de réponse.
Évaluation
D’un point de vue implémentation, pour calculer les métriques énoncées ci-dessus, le mieux est d’utiliser le package python evaluate d’Hugging Face.
Les résultats des performances des différents modèles considérés sont disponibles dans le tableau ci-dessous.
| Modèle | Paramètres | Contexte | Exact_match | F1 | Answer_F1 | NoAnswer_F1 |
|---|---|---|---|---|---|---|
| etalab/camembert-base-squadFR-fquad-piaf | 110M | 512 tokens | 39,30 | 51,55 | 79,54 | 23,58 |
| QAmembert | 110M | 512 tokens | 77,14 | 86,88 | 75,66 | 98,11 |
| QAmembert2 | 112M | 1024 tokens | 76,47 | 88,25 | 78,66 | 97,84 |
| ModernQAmembert | 136M | 8192 tokens | 76,73 | 88,85 | 79,45 | 98,24 |
| QAmembert-large | 336M | 512 tokens | 77,14 | 88,74 | 78,83 | 98,65 |
| QAmemberta | 111M | 1024 tokens | 78,18 | 89,53 | 81,40 | 97,64 |
En observant la colonne "Answer_f1", le modèle d’Etalab apparait comme compétitif sur des textes où la réponse à la question est bien dans le texte fourni (il fait mieux que le QAmemBERT-large par exemple). Néanmoins le fait qu'il ne gère pas les textes où la réponse à la question n'est pas dans le texte fourni le dessert.
Dans tous les cas de figures, que ce soit au niveau des métriques ou du nombre de paramètres et la taille de contexte gérée, le QAmemBERTa obtient les meilleurs résultats.
Nous invitions donc le lecteur à privilégier ce modèle.
Exemples d’utilisations
Lorsque la réponse est contenue dans le contexte :
from transformers import pipeline
qa = pipeline('question-answering', model='CATIE-AQ/QAmembert', tokenizer='CATIE-AQ/QAmembert')
result = qa({
'question': "Combien de personnes utilisent le français tous les jours ?",
'context': "Le français est une langue indo-européenne de la famille des langues romanes dont les locuteurs sont appelés francophones. Elle est parfois surnommée la langue de Molière. Le français est parlé, en 2023, sur tous les continents par environ 321 millions de personnes : 235 millions l'emploient quotidiennement et 90 millions en sont des locuteurs natifs. En 2018, 80 millions d'élèves et étudiants s'instruisent en français dans le monde. Selon l'Organisation internationale de la francophonie (OIF), il pourrait y avoir 700 millions de francophones sur Terre en 2050."
})
if result['score'] < 0.01:
print("La réponse n'est pas dans le contexte fourni.")
else :
print(result['answer'])
235 millions
# details
result
{'score': 0.9945194721221924
'start': 269,
'end': 281,
'answer': '235 millions'}
Lorsque la réponse n’est pas contenue dans le contexte :
from transformers import pipeline
qa = pipeline('question-answering', model='CATIE-AQ/QAmembert', tokenizer='CATIE-AQ/QAmembert')
result = qa({
'question': "Quel est le meilleur vin du monde ?",
'context': "La tour Eiffel est une tour de fer puddlé de 330 m de hauteur (avec antennes) située à Paris, à l’extrémité nord-ouest du parc du Champ-de-Mars en bordure de la Seine dans le 7e arrondissement. Son adresse officielle est 5, avenue Anatole-France.
Construite en deux ans par Gustave Eiffel et ses collaborateurs pour l'Exposition universelle de Paris de 1889, célébrant le centenaire de la Révolution française, et initialement nommée « tour de 300 mètres », elle est devenue le symbole de la capitale française et un site touristique de premier plan : il s’agit du quatrième site culturel français payant le plus visité en 2016, avec 5,9 millions de visiteurs. Depuis son ouverture au public, elle a accueilli plus de 300 millions de visiteurs."
})
if result['score'] < 0.01:
print("La réponse n'est pas dans le contexte fourni.")
else :
print(result['answer'])
La réponse n'est pas dans le contexte fourni.
# details
result
{'score': 3.619904940035945e-13,
'start': 734,
'end': 744,
'answer': 'visiteurs.'}
Si vous souhaitez tester le modèle de manière plus directe, un démonstrateur a été créé et est hébergé sous la forme d’un Space sur Hugging Face disponible ici ou bien ci-dessous :
Améliorations possibles
Terminons en listant des améliorations possibles à ce travail.
Premièrement, il serait intéressant de faire varier le nombre de questions sans réponse. En effet, dans une logique de simplification du processus, nous avons doublé le nombre de questions via notre processus de création de données sans réponse. On peut suspecter que cela a un impact sur les performances. En effet, on peut observer que le score F1 des données sans réponse est d’au moins 10 points supérieur à celui des questions avec réponses. Dans une logique d’équilibrage de ces deux scores F1, on pourrait envisager de réduire le nombre de questions sans réponse. Le jeu de données SQuAD 2.0 utilise pour sa part une répartition 66% (avec réponses)/33% (sans réponse) contre 50%/50% pour notre part.
Deuxièmement, il faudrait équilibrer les différents types de questions (qui ? quoi ? où ? pourquoi ? comment ? quand ? etc.). L’objectif étant d’avoir un modèle qui soit performant quel que soit le type de questions utilisé. Actuellement, la répartition est la suivante :
| Type de question | Fréquence en pourcentage |
| Que (quel, quelle, que, qu’est-ce que, etc.) | 55,12 |
| Qui | 16,24 |
| Combien | 7,56 |
| Quand | 6,85 |
| Où | 3,98 |
| Comment | 3,76 |
| Quoi (à quoi, en quoi, etc.) | 2,94 |
| Pourquoi | 1,41 |
| Autre | 2,14 |
Dans la même logique, on pourrait augmenter le nombre de question comportant une négation, par exemple « Quel est le nom du premier professeur de musique de Chopin qui n'était pas un musicien amateur ? », qui ne représente que 3,07% des questions actuellement.
Ce point nécessiterait cependant de l’investissement dans l’annotation de nouvelles données bien que le premier point cité puisse aider dans le rééquilibrage. Une alternative pourrait être de scrapper des données en ligne en open-source : on peut par exemple penser à des annales de brevet et plus généralement d’exercices demandant à des élèves de répondre à une question en citant un extrait issu d’un texte.
Troisièmement, on peut envisager d’incorporer une part de données sans réponse dans le contexte qui soit issue d’autres corpus que ceux utilisés ici. La logique que nous avons appliquée est de prendre des questions des corpus de type SQuAD 1.0 pour qu’une même question ait parfois une réponse et d’autres fois non afin que le modèle n’apprenne pas une réponse donnée à une question donnée et qu’ainsi il ne surapprenne pas.
L’idée d’ajouter des questions sans réponse (avec un contexte associé inédit) ne faisant pas partie des jeux de données de type SQuAD 1.0 est d’augmenter la variabilité des questions possibles vues par le modèle. Quelques jeux de données existent en français. On peut citer par exemple :
- Mkqa de Longpre et al. (2021) qui est un jeu de données multilingues comportant 10 000 questions en français. Une information intéressante qui est spécifiée dans ce jeu de données est le type de la question (qui ? quoi ? quand ? etc.)
- X-CSR de Lin et al. (2021) contient deux sous-ensembles. En ce qui concerne le QA, seul le sous-ensemble X-CSQA contenant 2 074 questions et réponses est pertinent.
C’est ainsi 12 074 questions en français qui sont disponibles dans la méthodologie SQuAD 2.0.
Enfin, il serait pertinent de créer un nouveau jeu de données de test pour la recherche et ne plus utiliser le jeu de données FQuAD 1.0 dev répandu actuellement. En effet, ce jeu de données est sous licence restrictive et ne permet pas de partager une augmentation de celui-ci au format SQuAD 2.0.
Conclusion
Nous introduisons le modèle QAmembert en quatre versions. Elles sont toutes librement accessibles gratuitement sur Hugging Face.
Ces modèles sont les premiers en français adoptant la méthodologie SQuAD 2.0 en open-source.
Nous n’excluons pas des travaux complémentaires afin notamment d’équilibrer le type de questions.
Citations
Modèles
@misc {qamemberta2024,
author = { {BOURDOIS, Loïck} },
organization = { {Centre Aquitain des Technologies de l'Information et Electroniques} },
title = { QAmemberta (Revision 976a70b) },
year = 2024,
url = { https://huggingface.co/CATIE-AQ/QAmemberta },
doi = { 10.57967/hf/3639 },
publisher = { Hugging Face }
}
@misc {qamembert2023,
author = { {ALBAR, Boris and BEDU, Pierre and BOURDOIS, Loïck} },
organization = { {Centre Aquitain des Technologies de l'Information et Electroniques} },
title = { QAmembert (Revision 9685bc3) },
year = 2023,
url = { https://huggingface.co/CATIE-AQ/QAmembert},
doi = { 10.57967/hf/0821 },
publisher = { Hugging Face }
}
Jeux de données
@misc {frenchQA2023,
author = { {ALBAR, Boris and BEDU, Pierre and BOURDOIS, Loïck} },
organization = { {Centre Aquitain des Technologies de l'Information et Electroniques} },
title = { frenchQA (Revision 6249cd5) },
year = 2023,
url = { https://huggingface.co/CATIE-AQ/frenchQA },
doi = { 10.57967/hf/0862 },
publisher = { Hugging Face }
}
Références
- SQuAD: 100,000+ Questions for Machine Comprehension of Text de Rajpurkar et al. (2016)
- Know What You Don't Know: Unanswerable Questions for SQuAD de Rajpurkar et al. (2018)
- FQuAD: French Question Answering Dataset de Hoffschmidt et al. (2020)
- FQuAD2.0: French Question Answering and knowing that you know nothing de Heinrich et al. (2021)
- Project PIAF: Building a Native French Question-Answering Dataset de Keranon et al. (2020)
- Newsquadfr de Lincoln (2021)
- Something new in French Text Mining and Information Extraction (Universal Chatbot): Largest Q&A French training dataset (110 000+) de Kabbadj (2018)
- CamemBERT: a Tasty French Language Model de Martin et al. (2019)
- FlauBERT: Unsupervised Language Model Pre-training for French de He et al. (2019
- CamemBERT 2.0: A Smarter French Language Model Aged to Perfection de Antoun et al. (2024)
- ModernBERT or DeBERTaV3? Examining Architecture and Data Influence on Transformer Encoder Models Performance de Antoun et al. (2025)
- Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference de Warner, Chaffin, Clavié et al. (2024)
- On the Usability of Transformers-based models for a French Question-Answering task de Cattan et al. (2021)
- SQuAD v2 French Translated de Pragnakalp Techlabs (2022)
- MKQA: A Linguistically Diverse Benchmark for Multilingual Open Domain Question Answering de Longpre et al. (2021)
- Common Sense Beyond English: Evaluating and Improving Multilingual Language Models for Commonsense Reasoning de Lin et al. (2021)