Avant-propos
La version initiale de cet article de blog a été mise en ligne en janvier 2024.
Une actualisation a eu lieu en novembre 2024 pour référencer quatre nouveaux modèles.
Une nouvelle actualisation a eu lieu en avril 2025 pour référencer deux nouveaux modèles.
Qu’est-ce que la reconnaissance d’entités nommées ?
La reconnaissance d’entités nommées (souvent abrégée en NER d’après l’anglais Named Entity Recognition) est une tâche de NLP consistant à étiqueter les séquences de mots d’un texte qui sont des noms de choses (personnes, sociétés, lieux, maladies, etc.).
D’un point de vue technique, la tâche de NER peut être considérée comme de la classification où au lieu de classifier au niveau de la phrase entière (pour de l’analyse de sentiment par exemple), l’on classifie au niveau du mot en indiquant à quelle classe appartient le mot traité.
Jeux de données de NER
Le jeu de données le plus connu et faisant référence en NER, est le jeu de données CoNLL-2003 (Conference on Computational Natural Language Learning) de Erik F. Tjong Kim Sang et Fien De Meulderet (2003). Créé pour l’anglais et l’allemand, les autres langues ont généralement adopté son formatage.
Ci-dessous un exemple de lignes de ce jeu de données :
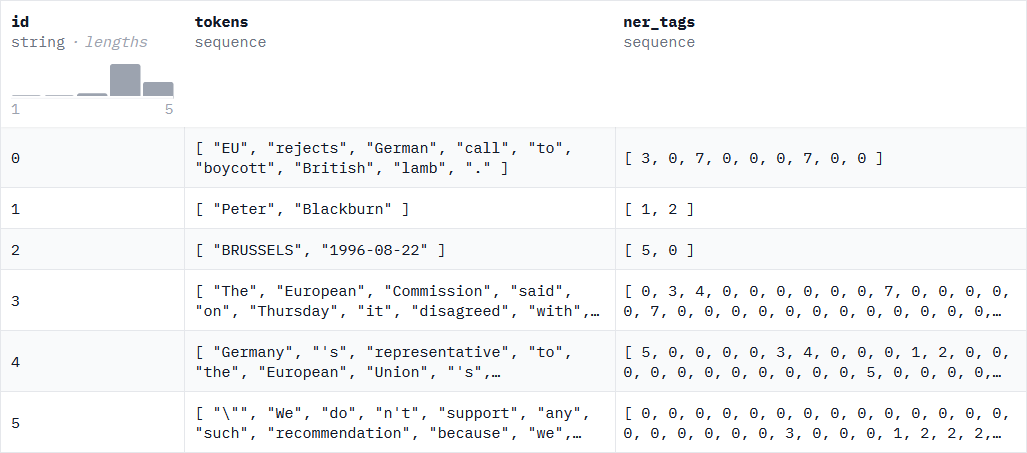
En ce qui concerne le français, des jeux de données ont été créés suivant la méthodologie de CoNLL-2003. On peut citer :
- WikiNER de Nothman et al. (2013) qui est un jeu de données (pour la partie en français) de 120 682 données d’entraînement et 13 410 de test. Les entités annoncées sont LOC (Localisations), ORG (Organisations), PER (Personnalités) et MISC (Divers) et sont réparties de la façon suivante :
| Split | O | PER | LOC | ORG | MISC |
|---|---|---|---|---|---|
| train | 2 781 968 | 116 633 | 140 345 | 41 547 | 73 411 |
| test | 305 131 | 13 345 | 15 220 | 3 896 | 8 183 |
- Wikiann de Rahimi et al. (2019) based on Pan, Xiaoman, et al. (2019) qui est un jeu de données (pour la partie en français) avec 20 000 données d’entraînement, 10 000 de validation et 10 000 de test. Les entités annoncées sont LOC, ORG, PER et MISC et sont réparties de la façon suivante :
| Split | O | PER | LOC | ORG |
|---|---|---|---|---|
| train | 65 292 | 21 992 | 21 273 | 28 231 |
| validation | 32 167 | 10 826 | 10 826 | 14 401 |
| test | 32 612 | 11 027 | 10 844 | 14 271 |
- MultiNERD de Tedeschi et Navigli (2022) qui est un jeu de données (pour la partie en français) de 140 880 données d’entraînement, de 17 610 de validation et de 17 695 de test. Les entités annoncées sont PER, LOC, ORG, ANIM, BIO, CEL, DIS, EVE, FOOD, INST, MEDIA, PLANT, MYTH, TIME, VEHI et sont réparties de la façon suivante :
| Split | O | PER | LOC | ORG | ANIM | BIO | CEL | DIS | EVE | FOOD | INST | MEDIA | MYTH | PLANT | TIME | VEHI |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| train | 2 979 567 | 151 201 | 218 858 | 109 429 | 12 800 | 21 | 3 031 | 4 107 | 20 523 | 3 282 | 992 | 19 943 | 1 591 | 4 543 | 23 555 | 1 129 |
| validation | 402 643 | 17 599 | 14 151 | 3 498 | 766 | 0 | 392 | 698 | 2 009 | 795 | 157 | 1 444 | 541 | 832 | 6 456 | 156 |
| test | 406 146 | 18 591 | 14 124 | 3 685 | 844 | 6 | 390 | 709 | 2 137 | 776 | 174 | 1 615 | 453 | 654 | 4 872 | 96 |
- MultiCoNER v2 de Fetahu et al. (2023) qui est un jeu de données (pour la partie en français) de 120 682 données d’entraînement et 13 410 de test. Les entités annoncées sont Location (incluant Facility, OtherLOC, HumanSettlement, Station), Creative Work (incluant VisualWork, MusicalWork, WrittenWork, ArtWork, Software), Group (incluant MusicalGRP, PublicCORP, PrivateCORP, AerospaceManufacturer, SportsGRP, CarManufacturer, ORG), Person (incluant Scientist, Artist, Athlete, Politician, Cleric, SportsManager, OtherPER), Product (incluant Clothing, Vehicle, Food, Drink, OtherPROD), Medical (incluant Medication/Vaccine, MedicalProcedure, AnatomicalStructure, Symptom, Disease) et sont réparties de la façon suivante :
| Split | O | OtherPER | Artist | WrittenWork | VisualWork | Politician | HumanSettlement | ArtWork | Athlete | Facility | MusicalWork | MusicalGRP | ORG | Scientist | Cleric | PrivateCorp | SportsManager | OtherPROD | Software | PublicCorp | Disease | OtherLOC | Vehicle | AnatomicalStructure | Station | SportsGRP | Drink | Food | CarManufacturer | Symptom | Medication / Vaccine | Clothing | AerospaceManufacturer | MedicalProcedure |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| train | 196 008 | 3 748 | 7 268 | 4 536 | 3 588 | 2 456 | 5 864 | 408 | 2 908 | 2 240 | 1 304 | 1 242 | 2 670 | 630 | 930 | 390 | 650 | 1 504 | 1 040 | 800 | 564 | 588 | 824 | 556 | 754 | 1 482 | 466 | 672 | 488 | 410 | 506 | 426 | 418 | 424 |
| validation | 10 430 | 202 | 378 | 234 | 176 | 134 | 310 | 26 | 144 | 108 | 54 | 60 | 146 | 38 | 40 | 22 | 30 | 90 | 46 | 44 | 32 | 26 | 40 | 30 | 40 | 70 | 22 | 26 | 26 | 20 | 24 | 22 | 22 | 22 |
- Pii-masking-200k de la société ai4Privacy (2023) qui est un jeu de données (pour la partie en français) de 61 958 données d’entraînement. Les entités annoncées sont Prefix, Firstname, Lastname, Date, Time, Phoneimei, Username, Email, State, Jobarea, Url, City, Currency, Accountname, Creditcardnumber, Creditcardcvv, Phonenumber, Creditcardissuer, Currencysymbol, Amount, Sex, Useragent, Jobtitle, Ipv4, Ipv6, Jobtype, Companyname, Gender, Street, Secondaryaddress, County, Age, Accountnumber, IP, Ethereumaddress, Bitcoinaddress, Middlename, IBAN, Vehiclevrm, Dob, Pin, Password, Currencyname, Litecoinaddress, Currencycode, Buildingnumber, Ordinaldirection, Maskednumber, Zipcode, BIC, Nearbygpscoordinate, MAC, Vehiclevin, Eyecolor, Height et SSN, et sont réparties de la façon suivante :
| Split | Prefix | Firstname | Lastname | Date | Time | Phoneimei | Username | State | Jobarea | Url | City | Currency | Accountname | Creditcardnumber | Creditcardcvv | Phonenumber | Creditcardissuer | Currencysymbol | Amount | Sex | Useragent | Jobtitle | Ipv4 | Ipv6 | Jobtype | Companyname | Gender | Street | Secondaryaddress | County | Age | Accountnumber | IP | Ethereumaddress | Bitcoinaddress | Middlename | IBAN | Vehiclevrm | Dob | Pin | Password | Currencyname | Litecoinaddress | Currencycode | Buildingnumber | Ordinaldirection | Maskednumber | Zipcode | BIC | Nearbygpscoordinate | MAC | Vehiclevin | Eyecolor | Height | SSN | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| train | 3 980 | 20 081 | 6 114 | 5 832 | 3 587 | 2 924 | 3 502 | 5 201 | 3 659 | 3 550 | 3 462 | 3 406 | 2 318 | 3 566 | 3 882 | 1 219 | 3 366 | 2 017 | 3 874 | 3 684 | 4 042 | 3 207 | 3 534 | 3 489 | 3 426 | 3 971 | 3 571 | 3 876 | 3 753 | 3 696 | 3 740 | 3 924 | 3 491 | 2 971 | 2 151 | 3 412 | 3 718 | 3 006 | 1 145 | 4 098 | 999 | 3 807 | 1 078 | 1 113 | 1 093 | 3 887 | 1 920 | 3 304 | 3 728 | 1 040 | 2 908 | 1 597 | 1 013 | 1 528 | 1 472 | 3 334 |
Il s’agit ici des principaux jeux de données « propres », au sens qu’ils sont utilisables facilement car disponibles sur le Hub de Hugging Face. Nous verrons cependant dans la section suivante que la qualité des données de certains jeux de données cités à l’instant est questionnable et a donc nécessité un nettoyage avant de pouvoir les utiliser pour entraîner un modèle.
Il convient de noter qu’il existe d’autres jeux de données de NER en français. Cependant, ceux-ci sont soit de moindre qualité, nécessitent alors un prétraitement très lourd pour être exploitables, soit trop spécialisés. On peut par exemple citer les jeux de données suivants :
- Annotation référentielle du Corpus Arboré de Paris 7 en entités nommées (Referential named entity annotation of the Paris 7 French TreeBank) [in French] de Sagot et al. (2012) qui est utilisé dans la littérature scientifique comme benchmark du CamemBERT ou du FlauBERT par exemple mais qui n’est pas accessible librement.
- QUAERO de Névéol et al. (2014) qui est un jeu de données spécialisé dans le domaine médical.
- POLYGLOT-NER d’Al-Rfou et al. (2014) est un jeu de données issu de Wikipedia mais présentant d’importants doutes sur la qualité de l’annotation.
- Europeana Newspapers de Neudecker (2016) qui est un jeu de données obtenu par OCR de vieux journaux de la BnF.
- HIPE-2022 de Faggioli et al. (2022) qui regroupe quatre jeux de données (ajmc de Romanello et al. (2020), hipe2020 d’Ehrmann et al. (2020), letemps d’Ehrmann et al. (2016),
newseye d’Hamdi et al. (2021)) obtenus par OCR de vieux journaux (fin XIX - début XXème).
- DAWT de Spasojevic et al. (2017) n’est plus disponible en ligne suite au rachat de l’entreprise ayant créé ce jeu de données.
Dans le cadre de nos expérimentations, nous avons décidé de travailler avec deux configurations.
La première consiste à prendre en compte les entités LOC (Localisations), ORG (Organisations) et PER (Personnalités) permettant ainsi de travailler sur la concaténation des jeux MultiCONER, MultiNERD, Pii-masking-200k, Wikiann et WikiNER. C’est-à-dire que dans ce cas-ci, pour les jeux de données gérant d’autres entités que les trois considérées, nous réannotons ces entités supplémentaires à O (Other).
La seconde consiste à prendre en compte les entités LOC (Localisations), ORG (Organisations), PER (Personnalités) et MISC (Divers) permettant ainsi de travailler sur la concaténation des jeux MultiCONER, MultiNERD, Pii-masking-200k et WikiNER. C’est-à-dire que dans ce cas-ci, nous excluons Wikiann qui ne possède pas d’entités MISC et pour les jeux de données possédant des entités autres que LOC, ORG et PER mais pas explicitement MISC, nous réannotons ces entités supplémentaires en MISC.
Fuites de données et duplication
En nous intéressant à la qualité des jeux de données listés, nous avons pu constater qu’individuellement ils contenaient des fuites de données entre les échantillons d’entraînement et de test, ainsi que des données dupliquées.
A noter également qu’à l’issue du nettoyage individuel, un nettoyage supplémentaire doit être effectué. En effet, une donnée présente dans l’échantillon d’entraînement d’un jeu de données A et donc non présente dans l’échantillon de test de A, peut être présente dans l’échantillon de test de B, ce qui crée une fuite lors de la création du jeu de données A+B.
A titre d’information, les statistiques concernant le nombre de fuites et de duplications pour les cinq jeux de données de NER que nous avons retenus dans le cadre de nos expérimentations sont les suivantes :
- MultiCONER :
• Fuites entre l'échantillon d'entraînement et l'échantillon de test : 13 lignes soit 0,083 %
• Fuites entre l'échantillon de validation et l'échantillon de test : 0 lignes soit 0 %
• Lignes dupliquées dans l'échantillon d'entraînement : 170 lignes soit 1,081 %
• Lignes dupliquées dans l'échantillon de validation : 1 ligne soit 0,121 %
• Lignes dupliquées dans l'échantillon de test : 2 lignes soit 0,233 %
Ainsi entre les fuites et les duplications, les performances mesurées sur l’échantillon de test sont faussées d’au moins 1,754%.
- MultiNERD :
• Fuites entre l'échantillon d'entraînement et l'échantillon de test : 69 lignes soit 0,049 %
• Fuites entre l'échantillon de validation et l'échantillon de test : 20 lignes soit 0,114 %
• Lignes dupliquées dans l'échantillon d'entraînement : 2 600 lignes soit 1,846 %
• Lignes dupliquées dans l'échantillon de validation : 201 lignes soit 1,141 %
• Lignes dupliquées dans l'échantillon de test : 58 lignes soit 0,328 %
Ainsi entre les fuites et les duplications, les performances mesurées sur l’échantillon de test sont faussées d’au moins 0,833%.
- Pii-masking-200k :
Ce jeu de données ne contient ni fuites ni duplications de données.
- WikiNER :
• Fuites entre l'échantillon d'entraînement et l'échantillon de test : 22 lignes soit 0,019 %
• Fuites entre l'échantillon de validation et l'échantillon de test : 1 lignes soit 0,017 %
• Lignes dupliquées dans l'échantillon d'entraînement : 562 lignes soit 0,49 %
• Lignes dupliquées dans l'échantillon de validation : 5 lignes soit 0,127 %
• Lignes dupliquées dans l'échantillon de test : 17 lignes soit 0,127 %
Ainsi entre les fuites et les duplications, les performances mesurées sur l’échantillon de test sont faussées d’au moins 0,440%.
- Wikiann :
• Fuites entre l'échantillon d'entraînement et l'échantillon de test : 742 lignes soit 3,710 %
• Fuites entre l'échantillon de validation et l'échantillon de test : 473 lignes soit 4,730 %
• Lignes dupliquées dans l'échantillon d'entraînement : 1889 lignes soit 9,445 %
• Lignes dupliquées dans l'échantillon de validation : 700 lignes soit 7,000 %
• Lignes dupliquées dans l'échantillon de test : 644 lignes soit 6,440 %
Ainsi entre les fuites et les duplications, les performances mesurées sur l’échantillon de test sont faussées d’au moins 18,590%.
Nous pouvons constater que plus de 80% des jeux de données considérés contenaient des fuites ou des duplications.
Les statistiques concernant le nombre de fuites et de duplications pour la concaténation des cinq jeux de données de NER que nous avons retenus dans le cadre de nos expérimentations sont les suivantes :
- Configuration à 3 entités (LOC, ORG et PER) :
• Fuites entre l'échantillon d'entraînement et l'échantillon de test : 1071 lignes soit 0,371 %
• Fuites entre l'échantillon de validation et l'échantillon de test : 613 lignes soit 1,799 %
• Lignes dupliquées dans l'échantillon d'entraînement : 1839 lignes soit 0,638 %
• Lignes dupliquées dans l'échantillon de validation : 8 lignes soit 0,023 %
• Lignes dupliquées dans l'échantillon de test : 8 lignes soit 0,019 %
Ainsi entre les fuites et les duplications, les performances mesurées sur l’échantillon de test sont faussées d’au moins 4,015%.
- Configuration à 4 entités (LOC, ORG, PER et MISC) :
• Fuites entre l'échantillon d'entraînement et l'échantillon de test : 1028 lignes soit 0,384 %
• Fuites entre l'échantillon de validation et l'échantillon de test : 134 lignes soit 0,552 %
• Lignes dupliquées dans l'échantillon d'entraînement : 1779 lignes soit 0,664 %
• Lignes dupliquées dans l'échantillon de validation : 1 lignes soit 0,004 %
• Lignes dupliquées dans l'échantillon de test : 1 lignes soit 0,003 %
Ainsi entre les fuites et les duplications, les performances mesurées sur l’échantillon de test sont faussées d’au moins 3,647%.
Les jeux de données de NER nettoyés (sans fuites de données ni duplications) sont disponibles sur Hugging Face : frenchNER_3entities et frenchNER_4entities.
Quel modèle pour résoudre une tâche de NER ?
N’importe quel modèle de transformer est capable de résoudre cette tâche, que ce soit un transformer complet (encodeur et décodeur), un transformer décodeur, ou un transformer encodeur. Seule la façon dont sont fournies les données au modèle diffère entre les différentes approches.
En pratique, les modèles de type encodeur sont les plus utilisés. Du fait qu’ils sont les plus adaptés pour résoudre des tâches de classification, et probablement par habitude. En effet, dans le cas du français, les transformers encodeur ont été disponibles avant les transformers décodeur et les transformers complets.
Soulignons également que le modèle CamemBERT de Martin et al. (2019) semble davantage utilisé que le FlauBERT de He et al. (2019) pour la tâche de NER, sans qu’il n’y ait d’explications sur la raison.
En novembre 2024, Antoun et al. (2024) ont introduit le CamemBERT 2.0. Dans ce papier, ils proposent en réalité deux modèles : un CamemBERT2 et un CamemBERTa2. Ces modèles sont entraînés sur plus de données que dans leur première version et ont l'intérêt de pouvoir gérer une séquence de 1024 tokens contre 512 précédemment.
En avril 2025, Antoun et al. (2025) ont introduit le modernCamemBERT, une version en français du modernBERT de Warner, Chaffin, Clavié et al. et al. (2025) permettant de gérer une séquence de 8192 tokens.
Notons aussi qu’en plus du choix du modèle, la tâche de NER peut s’effectuer au niveau du token ou bien au niveau d’un n-gram de tokens consécutifs. Cette étendue de tokens ayant le nom de span dans la littérature.
Une librairie efficace et simple d’utilisation pour effectuer de la NER au niveau d’une span est SpanMarker de Tom Aarsen (2023).
Quelques modèles finetunés sur la tâche de NER sont disponibles en open-source. On peut lister :
- Le modèle Ner-french (un modèle Bi-LSTM) finetuné sur WikiNER au niveau du token par Flair et plus particulièrement Akbik et al. (2018)
- Le modèle Camembert-ner finetuné sur WikiNER au niveau du token par Jean-Baptiste Polle
- Le modèle DistillCamemBERT base finetuné sur WikiNER au niveau du token par le Crédit Mutuel et plus particulièrement par Delestre et Amar (2022)
La limite de ces modèles est qu’aucun d’entre eux n’utilise la totalité des données disponibles à disposition puisqu’ils sont tous les trois entraînés uniquement sur le jeu de données WikiNER. Cela a pour conséquence (cf. la partie évaluation) de spécialiser les modèles sur des données de type Wikipedia et bride alors leur capacité à généraliser sur de nouvelles données. De plus, comme indiqué précédemment, WikiNER possède des fuites de données et des duplications faussant les performances réelles des modèles.
De plus, aucun modèle de NER en français n’est disponible en taille large.
Compte tenu de ces limites, nous avons développé notre propre modèle au CATIE : le NERmembert. Celui-ci utilise l’ensemble des données de qualité à disposition en open-source et a été entraîné en plusieurs configurations. Le tout gratuitement et librement en open-source :
- https://huggingface.co/CATIE-AQ/NERmembert-base-3entities, modèle finetuné à partir d'almanach/camembert-base
- https://huggingface.co/CATIE-AQ/NERmembert-large-3entities, modèle finetuné à partir d'almanach/camembert-large
- https://huggingface.co/CATIE-AQ/NERmembert2-3entities, modèle finetuné à partir d'almanach/camembertv2-base
- https://huggingface.co/CATIE-AQ/NERmemberta-3entities, modèle finetuné à partir d'almanach/camembertav2-base
- https://huggingface.co/CATIE-AQ/Moderncamembert_3entities, modèle finetuné à partir d'almanach/moderncamembert-cv2-base
- https://huggingface.co/CATIE-AQ/NERmembert-base-4entities, modèle finetuné à partir d'almanach/camembert-base
- https://huggingface.co/CATIE-AQ/NERmembert-large-4entities, modèle finetuné à partir d'almanach/camembert-large
- https://huggingface.co/CATIE-AQ/NERmembert2-4entities, modèle finetuné à partir d'almanach/camembertv2-base
- https://huggingface.co/CATIE-AQ/NERmemberta-4entities, modèle finetuné à partir d'almanach/camembertav2-base
- https://huggingface.co/CATIE-AQ/Moderncamembert_4entities, modèle finetuné à partir d'almanach/moderncamembert-cv2-base
Métriques et évaluation
Quelles sont les performances des modèles ? Pour cela décrivons d’abord les métriques sur lesquelles sont évalués les modèles de NER.
Métriques
En NER, on donne généralement la précision, le rappel et le score F1 (qui est la moyenne harmonique des deux précédentes métriques) pour chaque entité ainsi qu’au global. L’accuracy peut également être renseignée.
Évaluation
D’un point de vue implémentation, pour calculer les métriques énoncées ci-dessus, le mieux est d’utiliser le package Python evaluate d’Hugging Face.
Cas à 3 entités
Ci-dessous, nous listons les tableaux des résultats des performances des différents modèles considérés dans la configuration à trois entités (PER, LOC, ORG) du jeu de données frenchNER_3entities.
Pour des raisons de place, nous ne présentons que le F1 des différents modèles. Vous pouvez consulter les résultats complets (i.e. toutes les métriques) dans les cartes de modèles disponibles sur Hugging Face.
|
Modèle |
Paramètres |
Contexte |
PER |
LOC |
ORG |
|---|---|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
110M |
512 tokens |
0,941 |
0,883 |
0,658 |
|
cmarkea/distilcamembert-base-ner |
67,5M |
512 tokens |
0,942 |
0,882 |
0,647 |
|
NERmembert-base-4entities |
110M |
512 tokens |
0,951 |
0,894 |
0,671 |
|
NERmembert-large-4entities |
336M |
512 tokens |
0,958 |
0,901 |
0,685 |
|
NERmembert-base-3entities |
110M |
512 tokens |
0,966 |
0,940 |
0,876 |
|
NERmembert2-3entities |
111M |
1024 tokens |
0,967 |
0,942 |
0,875 |
|
NERmemberta-3entities |
111M |
1024 tokens |
0,970 |
0,943 |
0,881 |
|
Moderncamembert_3entities |
136M |
8192 tokens |
0,969 |
0,944 |
0,881 |
|
NERmembert-large-3entities |
336M |
512 tokens |
0,969 |
0,947 |
0,890 |
On peut observer que les modèles NERmembert (quel que soit le nombre d’entités considérés) performent mieux que les autres modèles. Cela s’explique vraisemblablement par le fait qu’ils aient vu trois fois plus de données lors du finetuning.
De même, on peut voir que les modèles larges ont de meilleurs résultats que les modèles bases.
Notons que la différence de performance est particulièrement marquée entre les NERmembert 3 entités et les modèles non NERmembert avec des écarts de plus de 20 points sur l’entité ORG par exemple.
Les modèles NERmembert apparaissent comme plus généralistes comparés aux non NERmembert qui ont été entraînés uniquement sur le jeu de données WikiNER et donc spécialisés sur des données de type Wikipedia. Ils obtiennent d’ailleurs de meilleurs résultats que les NERmembert sur ce jeu de données là.
Nous constatons également ceci : alors que cmarkea/distilcamembert-base-ner annonce les meilleurs résultats sur WikiNER, une fois les fuites et duplications du jeu de données supprimées, c'est en réalité Jean-Baptiste/camembert-ner qui donne les meilleurs résultats.
Sachant que WikiNER et Wikiann sont tous deux basés sur Wikipédia, nous nous attendions à ce que ces deux modèles obtiennent de bonnes performances sur Wikiann également. A notre surprise, cela ne s'observe pas dans les résultats.
Enfin, on peut remarquer un écart entre le modèle NERmembert 3 entités et le modèle NERmembert 4 entités. La différence entre les deux configurations est que les NERmembert 3 entités ont vu un peu plus de données, à savoir le jeu de données Wikiann qui fait environ 25 000 lignes supplémentaires. Dans le détail des résultats par jeu de données disponibles ci-dessous, on peut d’ailleurs voir que le modèle base à 4 entités donne des performances équivalentes ou supérieures au modèle base à 3 entités sur les jeux de données qu’ils ont en commun mais rencontre des difficultés sur Wikiann.
Pour plus de détails, vous pouvez étendre l’onglet ci-après afin d’afficher les résultats obtenus pour chacun des jeux de données.
Résultats par jeux de données
MultiCoNER
|
Modèle |
PER |
LOC |
ORG |
|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
0,940 |
0,761 |
0,723 |
|
cmarkea/distilcamembert-base-ner |
0,921 |
0,748 |
0,694 |
|
NERmembert-base-3entities |
0,960 |
0,887 |
0,876 |
|
NERmembert2-3entities |
0,958 |
0,876 |
0,863 |
|
NERmemberta-3entities |
0,964 |
0,865 |
0,859 |
|
NERmembert-large-3entities |
0,965 |
0,902 |
0,896 |
MultiNERD
|
Modèle |
PER |
LOC |
ORG |
|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
0,962 |
0,934 |
0,888 |
|
cmarkea/distilcamembert-base-ner |
0,972 |
0,938 |
0,884 |
|
NERmembert-base-3entities |
0,985 |
0,973 |
0,938 |
|
NERmembert2-3entities |
0,985 |
0,972 |
0,933 |
|
NERmemberta-3entities |
0,986 |
0,974 |
0,945 |
|
NERmembert-large-3entities |
0,987 |
0,979 |
0,953 |
WikiNER
|
Modèle |
PER |
LOC |
ORG |
|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
0,986 |
0,966 |
0,938 |
|
cmarkea/distilcamembert-base-ner |
0,983 |
0,964 |
0,925 |
|
NERmembert-base-3entities |
0,969 |
0,945 |
0,878 |
|
NERmembert2-3entities |
0,969 |
0,946 |
0,866 |
|
NERmemberta-3entities |
0,971 |
0,948 |
0,885 |
|
NERmembert-large-3entities |
0,972 |
0,950 |
0,893 |
WikiAnn
|
Modèle |
PER |
LOC |
ORG |
|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
0,867 |
0,722 |
0,451 |
|
cmarkea/distilcamembert-base-ner |
0,862 |
0,722 |
0,451 |
|
NERmembert-base-3entities |
0,947 |
0,906 |
0,886 |
|
NERmembert2-3entities |
0,950 |
0,911 |
0,910 |
|
NERmemberta-3entities |
0,953 |
0,902 |
0,890 |
|
NERmembert-large-3entities |
0.949 |
0.912 |
0.899 |
Cas à 4 entités
Ci-dessous, nous listons les tableaux des résultats des performances des différents modèles considérés dans la configuration à quatre entités (PER, LOC, ORG, MISC) du jeu de données frenchNER_4entities.
|
Modèle |
Paramètres |
Contexte |
PER |
LOC |
ORG |
MISC |
|---|---|---|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
110M |
512 tokens |
0,971 |
0,947 |
0,902 |
0,663 |
|
cmarkea/distilcamembert-base-ner |
67,5M |
512 tokens |
0,974 |
0,948 |
0,892 |
0,658 |
|
NERmembert-base-4entities |
110M |
512 tokens |
0,978 |
0,958 |
0,903 |
0,814 |
|
NERmembert2-4entities |
111M |
1024 tokens |
0,978 |
0,958 |
0,901 |
0,806 |
| NERmemberta-4entities |
111M |
1024 tokens |
0,979 |
0,961 |
0,915 |
0,812 |
| Moderncamembert_4entities |
136M |
8192 tokens |
0,981 |
0,960 |
0,913 |
0,811 |
|
NERmembert-large-4entities |
336M |
512 tokens |
0,982 |
0,964 |
0,919 |
0,834 |
Encore une fois, pour des raisons de place, nous ne présentons que le F1 des différents modèles. Vous pouvez consulter les résultats complets (i.e. toutes les métriques) dans les cartes de modèles disponibles sur Hugging Face.
Les résultats sont dans le même sillon que ce qu’on peut observer pour la configuration à 3 entités.
A savoir que les modèles NERmembert (quel que soit le nombre d’entités considérés) performent mieux que les autres modèles et que les modèles larges ont de meilleurs résultats que les modèles bases.
Sur les entités PER, LOC et ORG, les NERmembert 3 entités ont des résultats semblables aux NERmembert 4 entités. L’intérêt des NERmembert 4 entités est qu’ils gèrent l’entité supplémentaire MISC.
A nouveau, les NERmembert apparaissent comme plus généralistes en comparaison aux non NERmembert. Comme pour la configuration à trois entités, ces modèles obtiennent de meilleurs résultats sur WikiNER mais ont des difficultés sur les autres jeux de données.
Il y a un écart important sur la catégorie MISC. Une explication pourrait être la nature de la définition de cette entité. En effet, pour WikiNER, il s’agit principalement de noms d’œuvres (livres ou films par exemple), là où MultiNERD et MultiCoNER gèrent en plus des noms médicaux (maladies/symptômes) et des produits (marques de véhicule/nourriture/vêtements).
Pour plus de détails, vous pouvez étendre l’onglet ci-après afin d’afficher les résultats obtenus pour chacun des jeux de données.
Résultats par jeux de données
MultiCoNER
|
Modèle |
PER |
LOC |
ORG |
MISC |
|---|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
0,940 |
0,761 |
0,723 |
0,560 |
|
cmarkea/distilcamembert-base-ner |
0,921 |
0,748 |
0,694 |
0,530 |
|
NERmembert-base-4entities |
0,960 |
0,890 |
0,867 |
0,852 |
|
NERmembert2-4entities |
0,964 |
0,888 |
0,864 |
0,850 |
|
NERmemberta-4entities |
0,966 |
0,891 |
0,867 |
0,862 |
|
NERmembert-large-4entities |
0,969 |
0,919 |
0,904 |
0,864 |
MultiNERD
|
Modèle |
PER |
LOC |
ORG |
MISC |
|---|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
0,962 |
0,934 |
0,888 |
0,419 |
|
cmarkea/distilcamembert-base-ner |
0,972 |
0,938 |
0,884 |
0,430 |
|
NERmembert-base-4entities |
0,985 |
0,973 |
0,938 |
0,770 |
|
NERmembert2-4entities |
0,986 |
0,974 |
0,937 |
0,761 |
|
NERmemberta-4entities |
0,987 |
0,976 |
0,942 |
0,770 |
|
NERmembert-large-4entities |
0,987 |
0,976 |
0,948 |
0,790 |
WikiNER
|
Modèle |
PER |
LOC |
ORG |
MISC |
|---|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
0,986 |
0,966 |
0,938 |
0,938 |
|
cmarkea/distilcamembert-base-ner |
0,983 |
0,964 |
0,925 |
0,926 |
|
NERmembert-base-4entities |
0,970 |
0,945 |
0,876 |
0,872 |
|
NERmembert2-4entities |
0,968 |
0,945 |
0,874 |
0,871 |
|
NERmemberta-4entities |
0,969 |
0,950 |
0,897 |
0,871 |
|
NERmembert-large-4entities |
0,975 |
0,953 |
0,896 |
0,893 |
Modèles de span
Nous avons listé ci-dessus des modèles entraînés au niveau du token. Nous avons également entraîné des modèles au niveau de n-gram de tokens consécutifs avec la librairie SpanMarker. La littérature sur le sujet (le mémoire de Tom Aarsen auteur de SpanMarker en fait une bonne synthèse) tend à indiquer que les modèles entraînés au niveau de span donnent de meilleures performances que les modèles entraînés au niveau du token.
Nous obtenons des résultats inverses dans nos expériences :
Cas à 3 entités
|
Modèle |
PER |
LOC |
ORG |
|---|---|---|---|
|
Span Marker (frenchNER_3entities) |
0,959 |
0,924 |
0,850 |
|
NERmembert-base-3entities |
0,966 |
0,940 |
0,876 |
Cas à 4 entités
|
Modèle |
PER |
LOC |
ORG |
MISC |
|---|---|---|---|---|
|
Span Marker (frenchNER_4entities) |
0,966 |
0,939 |
0,892 |
0,760 |
|
NERmembert-base-4entities |
0,978 |
0,958 |
0,903 |
0,814 |
Nous avançons deux possibilités à ces résultats. La première est que les performances peuvent varier en fonction des langues (Tom Aarsen nous ayant indiqué que des observations similaires ont été observées en espagnol).
La seconde est que les résultats obtenus en anglais sont biaisés et donc en réalité non fiables. En effet, le jeu de données CoNLL2003 qui est massivement utilisé en anglais contient lui aussi des fuites de données et duplications :
• Fuites entre l'échantillon d'entraînement et l'échantillon de test 78 lignes soit 0.556%.
• Fuites entre l'échantillon de validation et l'échantillon de test : 25 lignes soit 0.769%.
• Lignes dupliquées dans l'échantillon d'entraînement : 1 350 lignes soit 9.615%.
• Lignes dupliquées dans l'échantillon de validation : 269 lignes soit 8.277%.
• Lignes dupliquées dans l'échantillon de test : 269 lignes soit 7.79 %.
Ainsi entre les fuites et les duplications, les performances mesurées sur l’échantillon de test sont faussées d’au moins 10,77%.
Enfin, nous terminons cette section en soulignant que l’entraînement d’un modèle SpanMarker prend trois fois plus de temps qu’un NERmembert.
Exemple d’utilisations
from transformers import pipeline
ner = pipeline('token-classification', model='CATIE-AQ/NERmembert-base-4entities', tokenizer='CATIE-AQ/NERmembert-base-4entities', aggregation_strategy="simple")
results = ner(
"Le dévoilement du logo officiel des JO s'est déroulé le 21 octobre 2019 au Grand Rex. Ce nouvel emblème et cette nouvelle typographie ont été conçus par le designer Sylvain Boyer avec les agences Royalties & Ecobranding. Rond, il rassemble trois symboles : une médaille d'or, la flamme olympique et Marianne, symbolisée par un visage de femme mais privée de son bonnet phrygien caractéristique. La typographie dessinée fait référence à l'Art déco, mouvement artistique des années 1920, décennie pendant laquelle ont eu lieu pour la dernière fois les Jeux olympiques à Paris en 1924. Pour la première fois, ce logo sera unique pour les Jeux olympiques et les Jeux paralympiques."
)
print(results)
[{'entity_group': 'MISC', 'score': 0.9456432, 'word': 'JO', 'start': 36, 'end': 38},
{'entity_group': 'LOC', 'score': 0.9990527, 'word': 'Grand Rex', 'start': 75, 'end': 84},
{'entity_group': 'PER', 'score': 0.99884754, 'word': 'Sylvain Boyer', 'start': 165, 'end': 178},
{'entity_group': 'ORG', 'score': 0.99118334, 'word': 'Royalties & Ecobranding', 'start': 196, 'end': 219},
{'entity_group': 'PER', 'score': 0.9446552, 'word': 'Marianne', 'start': 299, 'end': 307},
{'entity_group': 'MISC', 'score': 0.97599506, 'word': 'Art déco', 'start': 438, 'end': 446},
{'entity_group': 'MISC', 'score': 0.99798834, 'word': 'Jeux olympiques', 'start': 550, 'end': 565},
{'entity_group': 'LOC', 'score': 0.7205312, 'word': 'Paris', 'start': 568, 'end': 573},
{'entity_group': 'MISC', 'score': 0.996698, 'word': 'Jeux olympiques', 'start': 635, 'end': 650},
{'entity_group': 'MISC', 'score': 0.9955608, 'word': 'Jeux paralympiques', 'start': 658, 'end': 676}]
Si vous souhaitez tester le modèle de manière plus directe, un démonstrateur a été créé et est hébergé sous la forme d’un Space sur Hugging Face disponible ici ou bien ci-dessous :
Améliorations possibles
Terminons en listant des améliorations possibles à ce travail.
Dans la section sur la description des données, nous avons listé les effectifs disponibles par type d’entités. Il est possible de relever un déséquilibre se ressentant par la suite sur les résultats (pour les entités ORG et MISC notamment). Un travail important consisterait ainsi à équilibrer les entités à notre disposition en effectuant par exemple de l’augmentation de données par simple substitution d’une valeur d’une entité par un autre du même type. Cela peut se faire en utilisant des entités déjà présentes dans notre jeu de données (ce qui pourrait permettre de rendre la valeur d’une entité plus robuste au contexte l’entourant) ou bien issues de sources externes (pour les ORG on peut penser à des données issues des chambres de commerce ou de l’INSEE par exemple).
Un autre travail consisterait à ajouter d’autres entités mais nécessiterait un effort conséquent d’annotation.
Conclusion
Nous introduisons le modèle NERmembert en huit versions différentes. L'ensemble des modèles entraînés sont accompagnés des jeux de données que nous avons utilisés qui sont sans fuites de données ou duplications. Le tout est librement accessible gratuitement sur Hugging Face.
Citations
Modèles
@misc {NERmemberta2024,
author = { {BOURDOIS, Loïck} },
organization = { {Centre Aquitain des Technologies de l'Information et Electroniques} },
title = { NERmemberta-3entities (Revision 989f2ee) },
year = 2024,
url = { https://huggingface.co/CATIE-AQ/NERmemberta-3entities },
doi = { 10.57967/hf/3640 },
publisher = { Hugging Face }
}
@misc {NERmembert2024,
author = { {BOURDOIS, Loïck} },
organization = { {Centre Aquitain des Technologies de l'Information et Electroniques} },
title = { NERmembert-large-4entities (Revision 1cd8be5) },
year = 2024,
url = { https://huggingface.co/CATIE-AQ/NERmembert-large-4entities },
doi = { 10.57967/hf/1752 },
publisher = { Hugging Face }
}
Jeux de données
@misc {frenchNER2024,
author = { {BOURDOIS, Loïck} },
organization = { {Centre Aquitain des Technologies de l'Information et Electroniques} },
title = { frenchNER_4entities (Revision f1e8fef) },
year = 2024,
url = { https://huggingface.co/datasets/CATIE-AQ/frenchNER_4entities },
doi = { 10.57967/hf/1751 },
publisher = { Hugging Face }
}
Références
- Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition de Erik F. Tjong Kim Sang et Fien De Meulder (2003)
- http://dx.doi.org/10.1016/j.artint.2012.03.006">Learning multilingual named entity recognition from Wikipedia de Nothman et al. (2013)
- Massively Multilingual Transfer for NER de Rahimi et al. (2019)
- Massively Multilingual Transfer for NER de Pan, Xiaoman, et al. (2019)
- MultiNERD: A Multilingual, Multi-Genre and Fine-Grained Dataset for Named Entity Recognition (and Disambiguation) de Tedeschi et Navigli (2022)
- SemEval-2023 Task 2: Fine-grained Multilingual Named Entity Recognition (MultiCoNER 2) de Fetahu et al. (2023)
- Pii-masking-200k d’ai4Privacy (2023)
- Annotation référentielle du Corpus Arboré de Paris 7 en entités nommées (Referential named entity annotation of the Paris 7 French TreeBank) [in French] de Sagot et al. (2012)
- The Quaero French Medical Corpus: A Ressource for Medical Entity Recognition and Normalization de Névéol et al. (2014)
- POLYGLOT-NER: Massive Multilingual Named Entity Recognition d’Al-Rfou et al. (2014)
- Europeana Newspapers de Neudecker (2016)
- HIPE-2022 de Faggioli et al. (2022)
- ajmc de Romanello et al. (2020)
- Overview of CLEF HIPE 2020: Named Entity Recognition and Linking on Historical Newspapers d’Ehrmann et al. (2020)
- Diachronic Evaluation of NER Systems on Old Newspapers d’Ehrmann et al. (2016)
- A Multilingual Dataset for Named Entity Recognition, Entity Linking and Stance Detection in Historical Newspapers d’Hamdi et al. (2021)
- DAWT: Densely Annotated Wikipedia Texts across multiple languages de Spasojevic et al. (2017)
- CamemBERT: a Tasty French Language Model de Martin et al. (2019)
- FlauBERT: Unsupervised Language Model Pre-training for French de He et al. (2019
- CamemBERT 2.0: A Smarter French Language Model Aged to Perfection de Antoun et al. (2024)
- ModernBERT or DeBERTaV3? Examining Architecture and Data Influence on Transformer Encoder Models Performance de Antoun et al. (2025)
- CamemBERT 2.0: A Smarter French Language Model Aged to Perfection de Antoun et al. (2024)
- SpanMarker d’Aarsen (2023)
- ner-french d’Akbik et al. (2018)
- camembert-ner de Polle (2021)
- distilcamembert de Delestre et Amar (2022)