Foreword
The original version of this blog post was published in January 2024.
An update took place in November 2024 to reference four new models.
A new update was made in April 2025 to reference two new models.
What is named entity recognition?
Named Entity Recognition, often abbreviated as NER, is a task in Natural Language Processing (NLP) that involves labeling sequences of words in a text that represents names entities such as people, companies, places, diseases, etc.
From a technical point of view, the NER task can be considered as classification, where instead of classifying at the level of the whole sentence (for sentiment analysis, for example), we classify at the level of the word, indicating to which class the processed word belongs.
NER Datasets
The best-known and leading NER dataset is the CoNLL-2003 (Conference on Computational Natural Language Learning) dataset by Erik F. Tjong Kim Sang and Fien De Meulderet (2003). Initially created for English and German speakers, other languages have generally adopted its formatting.
Below an example of a line from this dataset:
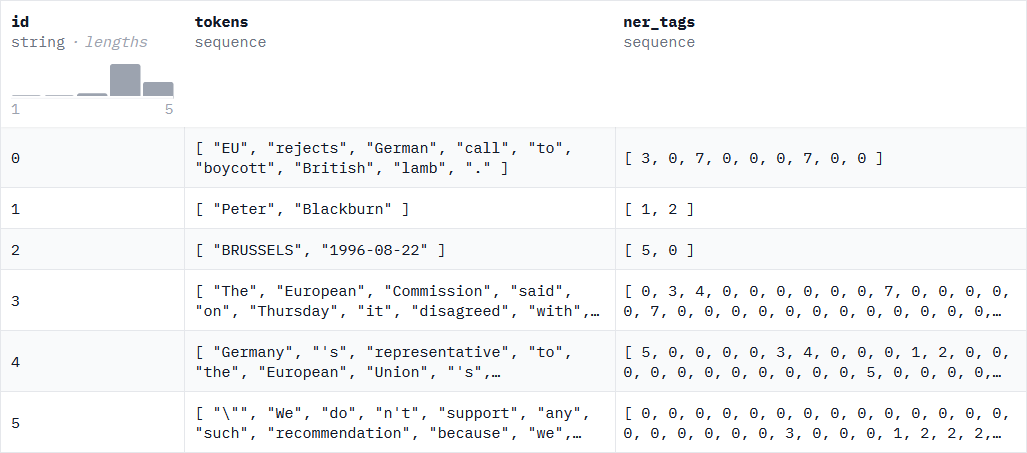
For French speakers, datasets have been created following the CoNLL-2003 methodology. These include:
- WikiNER by Nothman et al. (2013) which is a dataset (for the French part) of 120,682 training data and 13,410 test data. The entities announced are LOC (Locations), ORG (Organizations), PER (Personalities) and MISC (Miscellaneous) and are distributed as follows:
| Split | O | PER | LOC | ORG | MISC |
|---|---|---|---|---|---|
| train | 2,781,968 | 116,633 | 140,345 | 41,547 | 73,411 |
| test | 305,131 | 13,345 | 15,220 | 3,896 | 8,183 |
- Wikiann by Rahimi et al. (2019) based on Pan, Xiaoman, et al. (2019) which is a dataset (for the French part) with 20,000 training data, 10,000 validation data and 10,000 test data. The entities announced are LOC, ORG, PER and MISC and are distributed as follows:
| Split | O | PER | LOC | ORG |
|---|---|---|---|---|
| train | 65,292 | 21,992 | 21,273 | 28,231 |
| validation | 32,167 | 10,826 | 10,826 | 14,401 |
| test | 32,612 | 11,027 | 10,844 | 14,271 |
- MultiNERD by Tedeschi and Navigli (2022) which is a dataset (for the French part) of 140,880 training data, 17,610 validation data and 17,695 test data. The entities announced are PER, LOC, ORG, ANIM, BIO, CEL, DIS, EVE, FOOD, INST, MEDIA, PLANT, MYTH, TIME, VEHI and are distributed as follows:
| Split | O | PER | LOC | ORG | ANIM | BIO | CEL | DIS | EVE | FOOD | INST | MEDIA | MYTH | PLANT | TIME | VEHI |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| train | 2,979,567 | 151,201 | 218,858 | 109,429 | 12,800 | 21 | 3,031 | 4,107 | 20,523 | 3,282 | 992 | 19,943 | 1,591 | 4,543 | 23,555 | 1,129 |
| validation | 402,643 | 17,599 | 14,151 | 3,498 | 766 | NaN | 392 | 698 | 2,009 | 795 | 157 | 1,444 | 541 | 832 | 6,456 | 156 |
| test | 406,146 | 18,591 | 14,124 | 3,685 | 844 | 6 | 390 | 709 | 2,137 | 776 | 174 | 1,615 | 453 | 654 | 4,872 | 96 |
- MultiCONER v2 by Fetahu et al. (2023) which is a dataset (for the French part) of 120,682 training data and 13,410 test data. The entities announced are Location (including Facility, OtherLOC, HumanSettlement, Station), Creative Work (including VisualWork, MusicalWork, WrittenWork, ArtWork, Software), Group (including MusicalGRP, PublicCORP, PrivateCORP, AerospaceManufacturer, SportsGRP, CarManufacturer, ORG), Person (including Scientist, Artist, Athlete, Politician, Cleric, SportsManager, OtherPER), Product (including Clothing, Vehicle, Food, Drink, OtherPROD), Medical (including Medication/Vaccine, MedicalProcedure, AnatomicalStructure, Symptom, Disease) and are distributed as follows:
| Split | O | OtherPER | Artist | WrittenWork | VisualWork | Politician | HumanSettlement | ArtWork | Athlete | Facility | MusicalWork | MusicalGRP | ORG | Scientist | Cleric | PrivateCorp | SportsManager | OtherPROD | Software | PublicCorp | Disease | OtherLOC | Vehicle | AnatomicalStructure | Station | SportsGRP | Drink | Food | CarManufacturer | Symptom | Medication / Vaccine | Clothing | AerospaceManufacturer | MedicalProcedure |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| train | 196,008 | 3,748 | 7,268 | 4,536 | 3,588 | 2,456 | 5,864 | 408 | 2,908 | 2,240 | 1,304 | 1,242 | 2,670 | 630 | 930 | 390 | 650 | 1,504 | 1,040 | 800 | 564 | 588 | 824 | 556 | 754 | 1,482 | 466 | 672 | 488 | 410 | 506 | 426 | 418 | 424 |
| validation | 10,430 | 202 | 378 | 234 | 176 | 134 | 310 | 26 | 144 | 108 | 54 | 60 | 146 | 38 | 40 | 22 | 30 | 90 | 46 | 44 | 32 | 26 | 40 | 30 | 40 | 70 | 22 | 26 | 26 | 20 | 24 | 22 | 22 | 22 |
- Pii-masking-200k by the company ai4Privacy (2023) which is a dataset (for the French part) of 61,958 training data. The entities announced are Prefix, Firstname, Lastname, Date, Time, Phoneimei, Username, Email, State, Jobarea, Url, City, Currency, Accountname, Creditcardnumber, Creditcardcvv, Phonenumber, Creditcardissuer, Currencysymbol, Amount, Sex, Useragent, Jobtitle, Ipv4, Ipv6, Jobtype, Companyname, Gender, Street, Secondaryaddress, County, Age, Accountnumber, IP, Ethereumaddress, Bitcoinaddress, Middlename, IBAN, Vehiclevrm, Dob, Pin, Password, Currencyname, Litecoinaddress, Currencycode, Buildingnumber, Ordinaldirection, Maskednumber, Zipcode, BIC, Nearbygpscoordinate, MAC, Vehiclevin, Eyecolor, Height et SSN, and are distributed as follows:
| Split | Prefix | Firstname | Lastname | Date | Time | Phoneimei | Username | State | Jobarea | Url | City | Currency | Accountname | Creditcardnumber | Creditcardcvv | Phonenumber | Creditcardissuer | Currencysymbol | Amount | Sex | Useragent | Jobtitle | Ipv4 | Ipv6 | Jobtype | Companyname | Gender | Street | Secondaryaddress | County | Age | Accountnumber | IP | Ethereumaddress | Bitcoinaddress | Middlename | IBAN | Vehiclevrm | Dob | Pin | Password | Currencyname | Litecoinaddress | Currencycode | Buildingnumber | Ordinaldirection | Maskednumber | Zipcode | BIC | Nearbygpscoordinate | MAC | Vehiclevin | Eyecolor | Height | SSN | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| train | 3,980 | 20,081 | 6,114 | 5,832 | 3,587 | 2,924 | 3,502 | 5,201 | 3,659 | 3,550 | 3,462 | 3,406 | 2,318 | 3,566 | 3,882 | 1,219 | 3,366 | 2,017 | 3,874 | 3,684 | 4,042 | 3,207 | 3,534 | 3,489 | 3,426 | 3,971 | 3,571 | 3,876 | 3753 | 3,696 | 3,740 | 3,924 | 3,491 | 2,971 | 2,151 | 3,412 | 3,718 | 3,006 | 1,145 | 4,098 | 999 | 3,807 | 1,078 | 1,113 | 1,093 | 3,887 | 1,920 | 3,304 | 3,728 | 1,040 | 2,908 | 1,597 | 1,013 | 1,528 | 1,472 | 3,334 |
These datasets are considered “clean” as they are readily available on the Hugging Face Hub. However, as we will explore in the next section, the data quality of some of these datasets is questionable, necessitating cleaning before they can be used to train a model.
It should be noted that other NER datasets exist in French, but are either of lower quality, require extensive preprocessing to be usable, or are too specialized. Examples include the following datasets:
- Annotation référentielle du Corpus Arboré de Paris 7 en entités nommées (Referential named entity annotation of the Paris 7 French TreeBank) [in French] by Sagot et al. (2012) which is used in the scientific literature as a benchmark for CamemBERT or FlauBERT, for example, but which is not freely available.
- QUAERO by Névéol et al. (2014) which is a dataset specialized in the medical field.
- POLYGLOT-NER by Al-Rfou et al. (2014) is a dataset derived from Wikipedia but with significant doubts about the quality of the annotation.
- Europeana Newspapers by Neudecker (2016) which is a dataset obtained by OCR of old newspapers from the BnF.
- HIPE-2022 by Faggioli et al. (2022) which includes four datasets (ajmc by Romanello et al. (2020), hipe2020 by Ehrmann et al. (2020), letemps by Ehrmann et al. (2016), newseye by Hamdi et al. (2021)) obtained by OCR of old newspapers (late 19th - early 20th century).
- DAWT by Spasojevic et al. (2017) no longer available online following the buyout of the company that created the dataset.
In our experiments, we decided to work in two configurations.
The first one takes into account the LOC (Locations), ORG (Organizations) and PER (People) entities, enabling us to work on the concatenation of the MultiCONER, MultiNERD, Pii-masking-200k, Wikiann and WikiNER sets. That is, in this case, for datasets managing entities other than the three considered, we re-annotate these additional entities to O (Other).
The second approach involves considering the LOC (Locations), ORG (Organizations), PER (People) and MISC (Miscellaneous) entities, enabling us to work on the concatenation of the MultiCONER, MultiNERD, Pii-masking-200k and WikiNER datasets. In this scenario, we exclude Wikiann, which lacks MISC entities. Additionnaly, datasets containing entities other than LOC, ORG and PER but not explicitly categorized as MISC are re-annotated to include these entities as MISC.
Data leakage and duplication
Upon examining the quality of the listed datasets, we discovered that each of them individually contained data leaks between training and test samples, as well as duplicate data. Moreover, it should be noted that after completing individual cleaning, additional cleaning must be conducted at the aggregate level. This is because data present in the training sample of one dataset (A) but not in its test sample may be present in the test sample of another dataset (B), leading to a leak when the A+B dataset is formed.
By way of information, the statistics regarding the number of leaks and duplications for the five NER datasets we selected for our experiments are as follows:
- MultiCONER :
• Leakage between training split and test sample: 13 lines or 0.083%.
• Leaks between the validation split and the test split: 0 lines or 0%.
• Duplicated lines in the training split: 170 lines or 1.081%.
• Duplicated lines in the test split: 170 lines or 1.081%.
• Duplicated lines in the validation split: 1 lines or 0.242%.
• Duplicated lines in the test split: 2 lines or 0.233%.
Thus, between leaks and duplications, the performance measured on the test split is biased by at least 1.754%.
- MultiNERD :
• Leakage between training and test splits: 69 lines or 0.049%.
• Leaks between validation and test splits: 20 lines or 0.114%.
• Duplicated lines in the training split: 2,600 lines or 1.846%.
• Duplicated lines in the validation split: 58 lines or 0.329%.
• Duplicated lines in the test split: 58 lines or 0.328%.
Thus, between leaks and duplications, the performance measured on the test split is biased by at least 0.833%.
- Pii-masking-200k :
This dataset contains no data leaks or duplications.
- WikiNER :
• Leakage between training and test splits: 22 lines or 0.019%.
• Leakage between validation and test splits: 20 lines or 0.331%.
• Duplicated lines in the training split: 562 lines or 0.49%.
• Duplicated lines in the validation split: 17 lines or 0.282%.
• Duplicated lines in the test split: 17 lines or 0.127%.
Thus, between leaks and duplications, the performance measured on the test split is biased by at least 0.440%.
- Wikiann :
• Leakage between training and test splits: 742 lines or 3.710%.
• Leakage between validation split and test split: 473 lines or 4.730%.
• Duplicated lines in the training split: 1,889 lines or 9.445%.
• Duplicated lines in the validation split: 700 lines or 7,00%.
• Duplicated lines in the test split: 644 lines or 6.440%.
Thus, between leaks and duplications, the performance measured on the test split is biased by at least 18.590%.
We can see that over 80% of the datasets considered contained leaks or duplications.
The statistics concerning the number of leaks and duplications for the concatenation of the five NER datasets we selected for our experiments are as follows:
- 3-entity configuration (LOC, ORG and PER):
• Leakage between training and test splits: 1,071 lines or 0.371%.
• Leakage between validation split and test split: 613 lines or 1.799%.
• Duplicated lines in the training split: 1,839 lines or 0.638%.
• Duplicated lines in the validation split: 8 lines or 0.023%.
• Duplicated lines in the test split: 8 lines or 0.019%.
Thus, between leaks and duplications, the performance measured on the test split is biased by at least 4.015%.
- 4-entity configuration (LOC, ORG, PER and MISC):
• Leakage between training split and test split: 1,028 lines or 0.384%.
• Leaks between the validation split and the test split: 134 lines or 0.552%.
• Duplicated lines in the training split: 1,779 lines or 0.664%.
• Duplicated lines in the validation split: 1 lines or 0.004%.
• Duplicated lines in the test split: 1 lines or 0.003%.
Thus, between leaks and duplications, the performance measured on the test split is biased by at least 3.647%.
Cleaned NER datasets (with no data leaks or duplications) are available on Hugging Face: frenchNER_3entities and frenchNER_4entities.
Which model for solving a NER task?
Any transformer model can solve this task, whether it's a complete transformer (encoder and decoder), a transformer decoder, or a transformer encoder. Only the way in which data is supplied to the model differs between the different approaches.
In practice, encoder models are the most widely used, as they are best suited to solving classification tasks and are commonly utilized. This preference may stem from the fact that encoder transformers were available before decoder transformers and fully transformers, especially in the case of French.
It's worth noting that the CamemBERT model by Martin et al. (2019) appears to be more commonly used than FlauBERT by He et al. (2019) or the NER task, although the reason for this preference is not explicitly stated.
Note that in November 2024, Antoun et al. (2024) introduced CamemBERT 2.0. In this paper, they actually propose two models: a CamemBERT2 and a CamemBERTa2. These models are trained on more data than in their first version and have the advantage of being able to handle a sequence of 1024 tokens compared with 512 previously.
In April 2025, Antoun et al. (2025) introduced modernCamemBERT, a French-language version of modernBERT by <a href=“https://arxiv.org/abs/2504.08716”>Warner, Chaffin, Clavié et al. et al. (2025)</a> that manages a sequence of 8192 tokens.
Additionally, besides the choice of model, the NER task can be performed at the token level or at the level of an n-gram of consecutive tokens, referred to in the literature as a span. An efficient and user-friendly library for performing NER at the span level is SpanMarker by Tom Aarsen (2023).
A number of finetuned models for the NER task are available in open-source. These include:
- The ner-french model (a Bi-LSTM model) finetuned on WikiNER at the token level by Flair and more particularly Akbik et al. (2018)
- The Camembert-ner finetuned on WikiNER at the token level by Jean-Baptiste Polle
- The model DistillCamemBERT base finetuned on WikiNER at the token level by Crédit Mutuel and more particularly by Delestre and Amar (2022)
The limitation of these models is that none of them uses all the data available, as all three are trained solely on the WikiNER dataset.
This results in the specialization of the models on Wikipedia-type data, as seen in the evaluation section, thereby impeding their ability to generalize new data. What's more, as mentioned above, WikiNER contains data leakage and duplication, distorting the models' actual performance.
Additionally, it’s worth noting that no large-sized French NER model is currently available.
Given these limitations, we have developed our own model at CATIE: NERmembert. It uses all the quality data available in open-source and has been trained in several configurations. All free and open-source:
- https://huggingface.co/CATIE-AQ/NERmembert-base-3entities, model finetuned from almanach/camembert-base
- https://huggingface.co/CATIE-AQ/NERmembert-large-3entities, model finetuned from almanach/camembert-large
- https://huggingface.co/CATIE-AQ/NERmembert2-3entities, model finetuned from almanach/camembertv2-base
- https://huggingface.co/CATIE-AQ/NERmemberta-3entities, model finetuned from almanach/camembertav2-base
- https://huggingface.co/CATIE-AQ/Moderncamembert_3entities, model finetuned from d'almanach/moderncamembert-cv2-base
- https://huggingface.co/CATIE-AQ/NERmembert-base-4entities, model finetuned from almanach/camembert-base
- https://huggingface.co/CATIE-AQ/NERmembert-large-4entities, model finetuned from almanach/camembert-large
- https://huggingface.co/CATIE-AQ/NERmembert2-4entities, model finetuned from almanach/camembertv2-base
- https://huggingface.co/CATIE-AQ/NERmemberta-4entities, model finetuned from almanach/camembertav2-base
- https://huggingface.co/CATIE-AQ/Moderncamembert_4entities, model finetuned from d'almanach/moderncamembert-cv2-base
Metrics and evaluation
How do the models perform? Let's start by describing the metrics on which NER models are evaluated.
Metrics
In NER, precision, recall and F1 score (which is the harmonic mean of the previous two metrics) are generally given for each entity as well as globally. Accuracy can also be entered.
Evaluation
From an implementation point of view, it is advisable to utilize Hugging Face's evaluate Python package.
3-entity case
Below, we list the performance result tables for the different models considered in the three-entity configuration (PER, LOC, ORG) of the frenchNER_3entities dataset.
For reasons of space, we present only the F1 of the different models. You can view the full results (i.e. all metrics) in the model maps available at
Hugging Face.
|
Model |
Parameters |
Context |
PER |
LOC |
ORG |
|---|---|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
110M |
512 tokens |
0.941 |
0.883 |
0.658 |
|
cmarkea/distilcamembert-base-ner |
67.5M |
512 tokens |
0.942 |
0.882 |
0.647 |
|
NERmembert-base-4entities |
110M |
512 tokens |
0.951 |
0.894 |
0.671 |
|
NERmembert-large-4entities |
336M |
512 tokens |
0.958 |
0.901 |
0.685 |
|
NERmembert-base-3entities |
110M |
512 tokens |
0.966 |
0.940 |
0.876 |
|
NERmemberta-2entities |
111M |
1024 tokens |
0.967 |
0.942 |
0.875 |
|
NERmemberta-3entities |
111M |
1024 tokens |
0.970 |
0.943 |
0.881 |
|
NERmemberta-3entities |
136M |
8192 tokens |
0.969 |
0.944 |
0.881 |
|
NERmembert-large-3entities |
336M |
512 tokens |
0.969 |
0.947 |
0.890 |
We can observe that the NERmembert models (whatever the number of entities considered) perform better than the other models. This is probably because they saw three times as much data during the finetuning.
Similarly, we can see that the large models perform better than the base models.
Note that the difference in performance is particularly important between NERmembert 3 entities and non-NERmembert models, with differences of over 20 points on the ORG entity, for example.
The NERmembert models appear to be more generalist than the non-NERmembert models, which have only been trained on the WikiNER dataset and are therefore specialized on Wikipedia-type data.
In fact, they perform better than NERmembert on this dataset (see below).
We also note that while cmarkea/distilcamembert-base-ner announces the best results on WikiNER (once the leaks and duplications of the dataset have been removed), Jean-Baptiste/camembert-ner actually gives the best results.
One source of surprise for us, however, is that we anticipated these two models to perform well on the WikiAnn dataset, which is also derived from Wikipedia (with input texts shorter than those of WikiNER), a phenomenon not observed in the results.
Finally, there's a difference between the 3-entity and 4-entity NERmembert models. The difference between the two configurations is that the 3-entity NERmembert saw a little more data, namely the WikiAnn dataset, which is around 25,000 rows longer. In the detailed results per dataset below, we can see that the 4-entity model performs as well or better as the 3-entity model on the datasets they share, but has difficulties on WikiAnn.
For more details, you can expand the tab below to display the results obtained for each dataset.
Results by dataset
MultiCONER
|
Model |
PER |
LOC |
ORG |
|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
0.940 |
0.761 |
0.723 |
|
cmarkea/distilcamembert-base-ner |
0.921 |
0.748 |
0.694 |
|
NERmembert-base-3entities |
0.960 |
0.887 |
0.876 |
|
NERmembert2-3entities |
0.958 |
0.876 |
0.863 |
|
NERmemberta-3entities |
0.964 |
0.865 |
0.859 |
|
NERmembert-large-3entities |
0.965 |
0.902 |
0.896 |
MultiNERD
|
Model |
PER |
LOC |
ORG |
|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
0.962 |
0.934 |
0.888 |
|
cmarkea/distilcamembert-base-ner |
0.972 |
0.938 |
0.884 |
|
NERmembert-base-3entities |
0.985 |
0.973 |
0.938 |
|
NERmembert2-3entities |
0.985 |
0.972 |
0.933 |
|
NERmemberta-3entities |
0.986 |
0.974 |
0.945 |
|
NERmembert-large-3entities |
0.987 |
0.979 |
0.953 |
WikiNER
|
Model |
PER |
LOC |
ORG |
|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
0.986 |
0.966 |
0.938 |
|
cmarkea/distilcamembert-base-ner |
0.983 |
0.964 |
0.925 |
|
NERmembert-base-3entities |
0.969 |
0.945 |
0.878 |
|
NERmembert2-3entities |
0.969 |
0.946 |
0.866 |
|
NERmemberta-3entities |
0.971 |
0.948 |
0.885 |
|
NERmembert-large-3entities |
0.972 |
0.950 |
0.893 |
WikiAnn
|
Model |
PER |
LOC |
ORG |
|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
0.867 |
0.722 |
0.451 |
|
cmarkea/distilcamembert-base-ner |
0.862 |
0.722 |
0.451 |
|
NERmembert-base-3entities |
0.947 |
0.906 |
0.886 |
|
NERmembert2-3entities |
0.950 |
0.911 |
0.910 |
|
NERmemberta-3entities |
0.953 |
0.902 |
0.890 |
|
NERmembert-large-3entities |
0.949 |
0.912 |
0.899 |
4-entity case
Below, we list the tables of performance results for the various models considered in the four-entity configuration (PER, LOC, ORG, MISC) of the dataset frenchNER_4entities.
|
Model |
Parameters |
Context |
PER |
LOC |
ORG |
MISC |
|---|---|---|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
110M |
512 tokens |
0.971 |
0.947 |
0.902 |
0.663 |
|
cmarkea/distilcamembert-base-ner |
67.5M |
512 tokens |
0.974 |
0.948 |
0.892 |
0.658 |
|
NERmembert-base-4entities |
110M |
512 tokens |
0.978 |
0.958 |
0.903 |
0.814 |
|
NERmembert2-4entities |
111M |
1024 tokens |
0.978 |
0.958 |
0.901 |
0.806 |
| NERmemberta-4entities |
111M |
1024 tokens |
0.979 |
0.961 |
0.915 |
0.812 |
| Moderncamembert_4entities |
136M |
8192 tokens |
0.981 |
0.960 |
0.913 |
0.811 |
|
NERmembert-large-4entities |
336M |
512 tokens |
0.982 |
0.964 |
0.919 |
0.834 |
Again, for reasons of space, we only show the F1 of the various models. You can consult the complete results (i.e. all metrics) in the model cards available at Hugging Face.
The results are in line with those observed for the 3-entity configuration.
Namely, NERmembert models (whatever the number of entities considered) perform better than other models, and wide models perform better than basic models.
On PER, LOC and ORG entities, NERmembert 3 entities perform similarly to NERmembert 4 entities. The advantage of NERmembert 4 entities is that they handle the additional MISC entity.
Once again, NERmembert appear to be more generalist than non-NERmembert. As with the three-entity configuration, these models perform better on WikiNER, but have difficulties on other datasets.
There is a significant discrepancy on the MISC category. One explanation could be the nature of the definition of this entity. For WikiNER, it's mainly work names (books or films, for example), whereas MultiNERD and MultiCONER also handle medical names (diseases/symptoms) and products (vehicle brands/food/clothing).
For more details, you can expand the tab below to display the results obtained for each dataset.
Results by dataset
MultiCONER
|
Model |
PER |
LOC |
ORG |
MISC |
|---|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
0.940 |
0.761 |
0.723 |
0.560 |
|
cmarkea/distilcamembert-base-ner |
0.921 |
0.748 |
0.694 |
0.530 |
|
NERmembert-base-4entities |
0.960 |
0.890 |
0.867 |
0.852 |
|
NERmembert2-4entities |
0.964 |
0.888 |
0.864 |
0.850 |
|
NERmemberta-4entities |
0.966 |
0.891 |
0.867 |
0.862 |
|
NERmembert-large-4entities |
0.969 |
0.919 |
0.904 |
0.864 |
MultiNERD
|
Model |
PER |
LOC |
ORG |
MISC |
|---|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
0.962 |
0.934 |
0.888 |
0.419 |
|
cmarkea/distilcamembert-base-ner |
0.972 |
0.938 |
0.884 |
0.430 |
|
NERmembert2-4entities |
0.986 |
0.974 |
0.937 |
0.761 |
|
NERmemberta-4entities |
0.987 |
0.976 |
0.942 |
0.770 |
|
NERmembert-base-4entities |
0.985 |
0.973 |
0.938 |
0.770 |
|
NERmembert-large-4entities |
0.987 |
0.976 |
0.948 |
0.790 |
WikiNER
|
Model |
PER |
LOC |
ORG |
MISC |
|---|---|---|---|---|
|
Jean-Baptiste/camembert-ner |
0.986 |
0.966 |
0.938 |
0.938 |
|
cmarkea/distilcamembert-base-ner |
0.983 |
0.964 |
0.925 |
0.926 |
|
NERmembert-base-4entities |
0.970 |
0.945 |
0.876 |
0.872 |
|
NERmembert2-4entities |
0.968 |
0.945 |
0.874 |
0.871 |
|
NERmemberta-4entities |
0.969 |
0.950 |
0.897 |
0.871 |
|
NERmembert-large-4entities |
0.975 |
0.953 |
0.896 |
0.893 |
Span models
We've listed some token-level trained models above. We have also tested training models at the n-gram level of consecutive tokens with the SpanMarker library. Literature on the subject (Tom Aarsen’s thesis SpanMarker's author provides a good summary) suggests that models trained at span level perform better than models trained at token level.
Our experiments show the opposite results:
3-entity case
|
Model |
PER |
LOC |
ORG |
|---|---|---|---|
|
Span Marker (frenchNER_3entities) |
0.959 |
0.924 |
0.850 |
|
NERmembert-base-3entities |
0.966 |
0.940 |
0.876 |
4-entity case
|
Model |
PER |
LOC |
ORG |
MISC |
|---|---|---|---|---|
|
Span Marker (frenchNER_4entities) |
0.966 |
0.939 |
0.892 |
0.760 |
|
NERmembert-base-4entities |
0.978 |
0.958 |
0.903 |
0.814 |
There are two possible explanations for these results. The first is that performance may vary according to the language (Tom Aarsen told us that similar observations were made in Spanish).
The second is that the results obtained in English are biased and therefore unreliable. Indeed, the CoNLL2003 dataset, which is massively used in English, also contains data leaks and duplications:
• Leakage between training and test splits: 78 lines or 0.556%.
• Leakage between validation and test splits: 25 lines or 0.769%.
• Duplicated lines in the training split: 1,350 lines or 9.615%.
• Duplicated lines in the validation split: 269 lines or 8.277%.
• Duplicated lines in the test split: 269 lines or 7.79 %.
Thus, between leaks and duplications, the performance measured on the test split is biased by at least 10.77%.
Finally, we end this section by pointing out that training a SpanMarker model takes three times as long as training a NERmembert.
Example of use
from transformers import pipeline
ner = pipeline('token-classification', model='CATIE-AQ/NERmembert-base-4entities', tokenizer='CATIE-AQ/NERmembert-base-4entities', aggregation_strategy="simple")
results = ner(
"Le dévoilement du logo officiel des JO s'est déroulé le 21 octobre 2019 au Grand Rex. Ce nouvel emblème et cette nouvelle typographie ont été conçus par le designer Sylvain Boyer avec les agences Royalties & Ecobranding. Rond, il rassemble trois symboles : une médaille d'or, la flamme olympique et Marianne, symbolisée par un visage de femme mais privée de son bonnet phrygien caractéristique. La typographie dessinée fait référence à l'Art déco, mouvement artistique des années 1920, décennie pendant laquelle ont eu lieu pour la dernière fois les Jeux olympiques à Paris en 1924. Pour la première fois, ce logo sera unique pour les Jeux olympiques et les Jeux paralympiques."
)
print(results)
[{'entity_group': 'MISC', 'score': 0.9456432, 'word': 'JO', 'start': 36, 'end': 38},
{'entity_group': 'LOC', 'score': 0.9990527, 'word': 'Grand Rex', 'start': 75, 'end': 84},
{'entity_group': 'PER', 'score': 0.99884754, 'word': 'Sylvain Boyer', 'start': 165, 'end': 178},
{'entity_group': 'ORG', 'score': 0.99118334, 'word': 'Royalties & Ecobranding', 'start': 196, 'end': 219},
{'entity_group': 'PER', 'score': 0.9446552, 'word': 'Marianne', 'start': 299, 'end': 307},
{'entity_group': 'MISC', 'score': 0.97599506, 'word': 'Art déco', 'start': 438, 'end': 446},
{'entity_group': 'MISC', 'score': 0.99798834, 'word': 'Jeux olympiques', 'start': 550, 'end': 565},
{'entity_group': 'LOC', 'score': 0.7205312, 'word': 'Paris', 'start': 568, 'end': 573},
{'entity_group': 'MISC', 'score': 0.996698, 'word': 'Jeux olympiques', 'start': 635, 'end': 650},
{'entity_group': 'MISC', 'score': 0.9955608, 'word': 'Jeux paralympiques', 'start': 658, 'end': 676}]
If you'd like to test the model more directly, a demonstrator has been created and is hosted as a Space on Hugging Face available here or below:
Possible improvements
Let us conclude by listing some possible improvements to this work.
In the section on data description, we have listed the available number of entity by type. It is possible to identify an imbalance in the results (for ORG and MISC entities in particular). An important task would therefore be to balance the entities available to us by, for example, augmenting the data by simply substituting one entity value with another of the same type. This can be done using entities already present in our dataset (which could make the value of an entity more robust to the surrounding context) or from external sources (for ORGs, we can think of data from chambers of commerce or INSEE, for instance).
Another option would be to add other entities, but this would require a substantial annotation effort.
Conclusion
We introduce the NERmembert model in eight versions. All trained models come with the datasets we used, ensuring they are free from data leaks or duplications. All are accessible on Hugging Face for free.
Citations
Models
@misc {NERmemberta2024,
author = { {BOURDOIS, Loïck} },
organization = { {Centre Aquitain des Technologies de l'Information et Electroniques} },
title = { NERmemberta-3entities (Revision 989f2ee) },
year = 2024,
url = { https://huggingface.co/CATIE-AQ/NERmemberta-3entities },
doi = { 10.57967/hf/3640 },
publisher = { Hugging Face }
}
@misc {NERmembert2024,
author = { {BOURDOIS, Loïck} },
organization = { {Centre Aquitain des Technologies de l'Information et Electroniques} },
title = { NERmembert-large-4entities (Revision 1cd8be5) },
year = 2024,
url = { https://huggingface.co/CATIE-AQ/NERmembert-large-4entities },
doi = { 10.57967/hf/1752 },
publisher = { Hugging Face }
}
Datasets
@misc {frenchNER2024,
author = { {BOURDOIS, Loïck} },
organization = { {Centre Aquitain des Technologies de l'Information et Electroniques} },
title = { frenchNER_4entities (Revision f1e8fef) },
year = 2024,
url = { https://huggingface.co/datasets/CATIE-AQ/frenchNER_4entities },
doi = { 10.57967/hf/1751 },
publisher = { Hugging Face }
}
References
- Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition by Erik F. Tjong Kim Sang and Fien De Meulder (2003)
- http://dx.doi.org/10.1016/j.artint.2012.03.006">Learning multilingual named entity recognition from Wikipedia by Nothman et al. (2013)
- Massively Multilingual Transfer for NER by Rahimi et al. (2019)
- Massively Multilingual Transfer for NER by Pan, Xiaoman, et al. (2019)
- MultiNERD: A Multilingual, Multi-Genre and Fine-Grained Dataset for Named Entity Recognition (and Disambiguation) by Tedeschi and Navigli (2022)
- SemEval-2023 Task 2: Fine-grained Multilingual Named Entity Recognition (MultiCONER 2) by Fetahu et al. (2023)
- Annotation référentielle du Corpus Arboré de Paris 7 en entités nommées (Referential named entity annotation of the Paris 7 French TreeBank) [in French] by Sagot et al. (2012)
- Pii-masking-200k by ai4Privacy (2023)
- The Quaero French Medical Corpus: A Ressource for Medical Entity Recognition and Normalization by Névéol et al. (2014)
- POLYGLOT-NER: Massive Multilingual Named Entity Recognition by Al-Rfou et al. (2014)
- Europeana Newspapers by Neudecker (2016)
- HIPE-2022 by Faggioli et al. (2022)
- ajmc by Romanello et al. (2020)
- Overview of CLEF HIPE 2020: Named Entity Recognition and Linking on Historical Newspapers by Ehrmann et al. (2020)
- Diachronic Evaluation of NER Systems on Old Newspapers by Ehrmann et al. (2016)
- A Multilingual Dataset for Named Entity Recognition, Entity Linking and Stance Detection in Historical Newspapers by Hamdi et al. (2021)
- DAWT: Densely Annotated Wikipedia Texts across multiple languages by Spasojevic et al. (2017)
- CamemBERT: a Tasty French Language Model by Martin et al. (2019)
- FlauBERT: Unsupervised Language Model Pre-training for French by He et al. (2019
- CamemBERT 2.0: A Smarter French Language Model Aged to Perfection by Antoun et al. (2024)
- ModernBERT or DeBERTaV3? Examining Architecture and Data Influence on Transformer Encoder Models Performance by Antoun et al. (2025)
- Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference by Warner, Chaffin, Clavié et al. (2024)
- SpanMarker by Aarsen (2023)
- ner-french by Akbik et al. (2018)
- camembert-ner by Polle (2021)
- distilcamembert by Delestre and Amar (2022)