Introduction
Facial recognition is a technology that enables automatic identification of people based on characteristic information extracted from pictures of their face. This technology has evolved significantly over the last three decades (Bromley et al. addressed a similar issue in 1994), particularly due to contributions from artificial intelligence and deep learning techniques.
Neural networks are now at the core of many devices and equipment used for identifying individuals. The design and integration of these networks naturally depend on the intended application and available hardware resources, as well as other important parameters such as the availability of datasets for training.
Facial recognition is often approached as a classification problem where a neural network is used to determine the most likely class of a picture with individual's face. However, this approach can be problematic in some cases because:
it requires a substantial set of labeled data that can be tedious to build and update,
- it requires a fairly substantial set of labeled data potentially tedious to build and update
- the corresponding network must be retrained whenever new classes (i.e., new individuals to be identified) need to be added
For instance, in cases where new individuals need to be recognized on the fly in a video stream, the classification approach is inappropriate. Instead, it is necessary to turn to solutions that require fewer material resources and computational time.
In these cases, implementation of architectures based on similarity calculation functions are preferred, to determine whether pictures of individuals to be identified match the representations of known individuals recorded in a database, which may be enriched in real-time as new faces are detected.
We present here a description of a solution of this type based on a siamese architecture that we have tested and implemented as part of the RoboCup@Home, an international competition in the field of service robotics, where robots must interact with human operators.
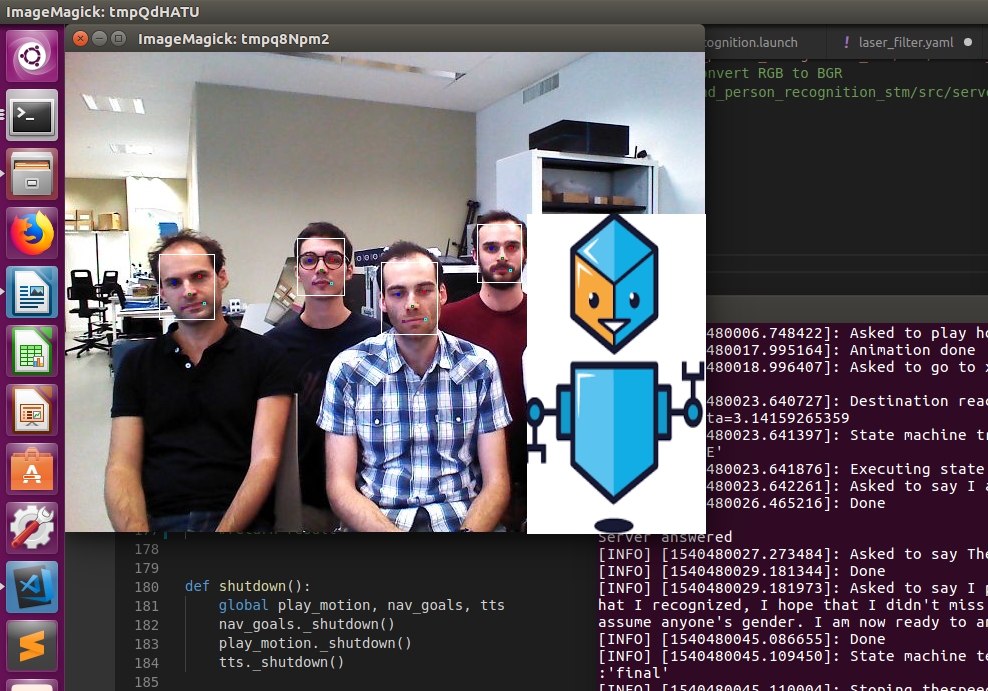
General architecture
Our facial recognition solution integrates a combination of tools and neural networks designed to perform the following tasks:
- Detect faces of individuals in pictures
- Create a 64-dimensional identity vector for each isolated face
- Calculate the distance between the vectors associated with two distinct images
- And determine whether the vector associated with one face is similar to another already identified by searching a database
Tools for face detection - in a picture or video stream - and extraction will be discussed later.
The core of the device consists of a model with an objective function that calculates a similarity score to determine if two face pictures refer to the same individual.
Our implemented architecture is siamese and involves two instances of the same convolutional neural network. Each one takes a picture of the face as input and provides a 64-dimensional vector representation of it as output.
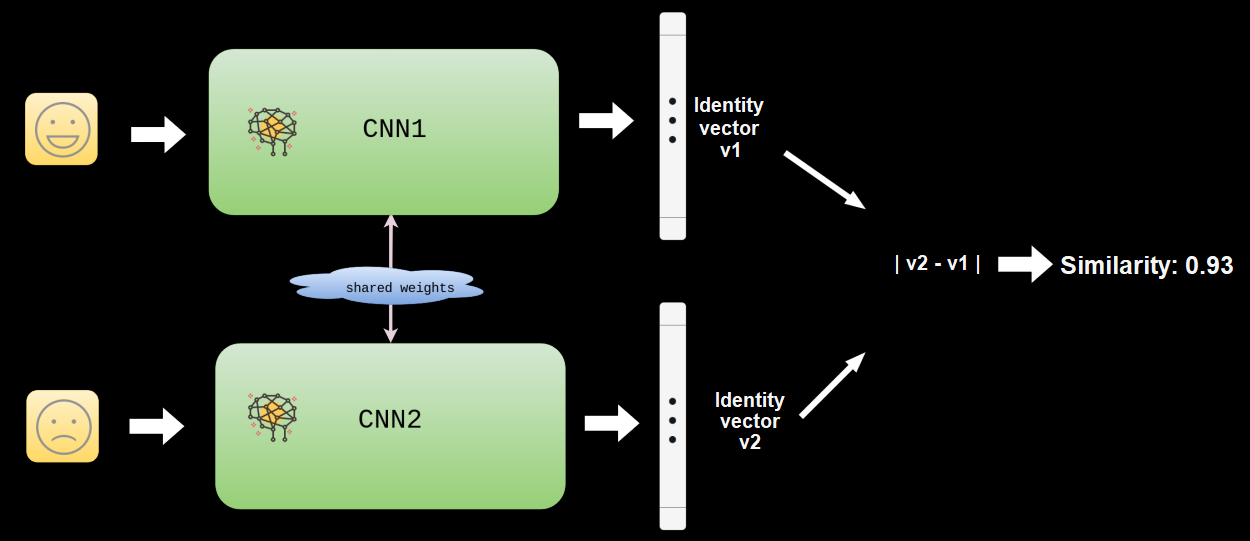
A convolutional neural network has been trained to provide close representations – in Euclidean distance - for two face images of the same person, and distant or very distant representations for images of two different people.
The outputs of the two network instances (identical in all points and therefore sharing the same configuration and the same weights) merge and are then used to calculate a similarity score based on the distance between the vector representations of the input images.
Each face detected in an image or video stream is then encoded by the network and compared to a set of known fingerprints stored in a database. The result of this comparison is returned as a scalar value (the similarity score mentioned earlier) and evaluated in the light of a predetermined threshold. If the similarity score exceeds the threshold, the fingerprints can be seen as identical and the individual is thus identified.
Network characteristics and drive
The challenge here is to design and train the convolutional network so that similar inputs are projected at relatively close locations in the performance space and, conversely, different inputs are projected at distant points.
Dataset used and pre-processing

The convolutional network used in this study was trained on the VGGFace2 dataset – by Cao et al. (2018)- which is a publicly accessible dataset containing around 3.3 million images of over 9000 individuals.
The images taken from this dataset with great variability in poses, age of subjects, exposures, etc., have been normalized so as to identify the faces and position the characteristic points of these (eyes, nose, mouth) in identical coordinates whatever the cliché considered.
The image normalization step is crucial for the network's performance. Face detection was performed using the RetinaFace neural network developed by Deng et al. (2019), which identifies the bounding box of the face as well as characteristic points. The image is then cropped and transformed to position the characteristic points in predetermined positions.
The convolutional network positioned at the core of our facial recognition device was then trained from these pictures.
Architecture
The architecture of our network is based on EfficientNet-B0, developed by Tan and Le (2019). This choice is a compromise between various constraints relevant to our problem, as the algorithm will be embedded in the robot with limited graphics card capabilities.
The number of parameters in memory is constrained, and the execution speed must be fast, as the people to be identified may move during the identification process.
This network offers relatively short inference times compared to deeper networks, which are more efficient but require significantly longer processing times.
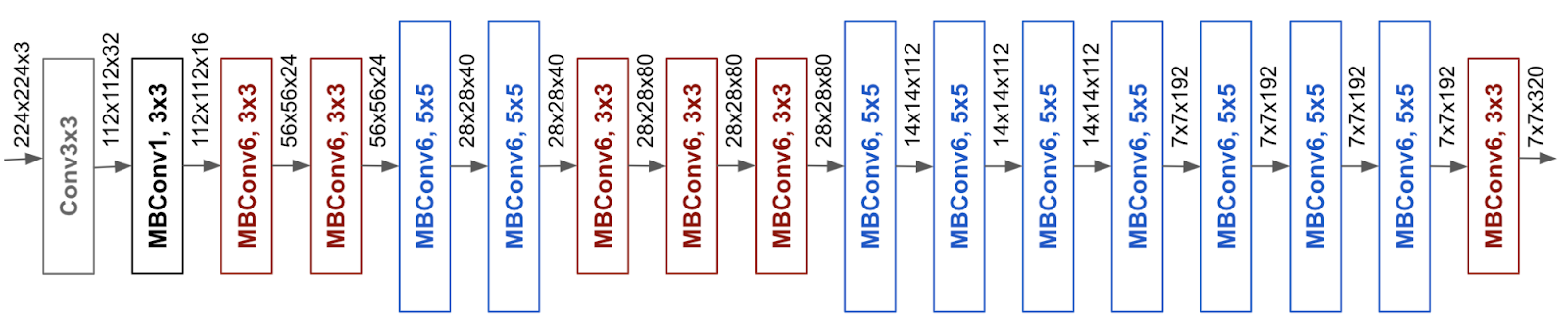
Notes:
- EfficientNet-B0 is the result of a field of research that holds an important place in deep learning: NAS (Neural Architecture Search), and which aims to automate and optimize the architectures of the networks used. It has given rise to many networks, the most popular of which are the MobileNets by Howard et al. (2017), EfficientNet (Tan and Le (2019)) or ConvNext by Liu et al. (2022).
- nowadays transformers for vision (ViT by Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zha et al. (2020)) are an alternative to convolutional neural networks. Examples include the Swin Transformer by Liu, Lin, Cao, Hu et al. (2021)
Choice of objective function
Learning similarities requires the use of appropriate objective functions, including the contrastive loss by Hadsell et al. (2005) and the triplet loss by Schroff et al. (2015).
The contrastive loss is defined by:
\(L(v_1, v_2)=\frac{1}{2} (1-\alpha)d(v_1, v_2)² + \frac{1}{2} \alpha(max(0,m-d(v_1, v_2)))²\)
where \(v_1\) and \(v_2\) being two vectors, α is a coefficient of 1 if the two vectors are of the same class, 0 otherwise, \(d\) is a function of any distance, and \(m\) is a real called the margin.
Intuitively, this objective function penalizes two vectors of the same class by their distance, while two vectors of different classes are penalized only if their distance is less than \(m\).
The function triplet loss involves a third vector, the anchor, in its equation:
\(L(a, v_1, v_2)=max(d(a,v_1)²-d(a,v_2)²+m, 0)\)
Here, \(a\) denotes the anchor, \(v_1\) is a vector of the same class as \(a\) and \(v_2\) is a vector of a different class of \(a\).
This function simultaneously tends to bring the pair \((a, v_1)\) closer together and to move away the pair \((a, v_2)\) as shown in the following figure:
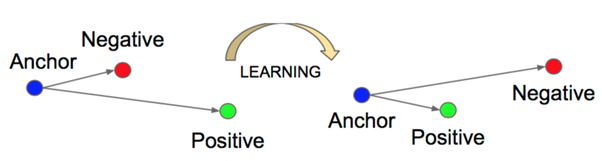
In general, training networks using these objective functions directly is quite expensive, the convergence of this type of system being longer to achieve than, for example, on conventional classification problems.
In order to circumvent this difficulty, we have adopted an alternative approach consisting of a two-step network training.
Training
We started by training the network on a classification task to recognize a person's picture from among 9,000 available identities, using a classical entropy function (crossentropy) as the cost function.
After achieving convergence on the classification task, we replaced the last classification layer with a new layer that represents the image embedding as the output.
The previous layers retained their weights from the previous training step. This approach is similar to transfer learning, where we aim to preserve the learned features during the classification task and reuse them to build the metric that interests us.
We then retrained the network with a contrastive or triplet objective function, as seen above.
This method enables us to quickly train a siamese network.

Implementation and integration
The facial recognition device was created by integrating various tools and scripts, mostly coded in Python.
The neural network itself is implemented using PyTorch, developed by Paszke, Gross, Chintala, Chanan et al. (2016), and specifically Pytorch Lightning, developed by Falcon et al. (2019). The network was trained using the computational resources provided by CATIE's VANIILA platform.
This approach enabled us to complete the successive training sessions within a reasonable time frame of less than two hours. The results were more than interesting, with an F1 score of 0.92, which outperforms the commercial solutions we tested.
Conclusion
In this article, we have described the process of facial recognition using a siamese network with an adapted cost function. We first extracted and aligned faces, and then trained the network on a large dataset of labeled images to address a face recognition problem.
However, a major limitation of this approach is the need for a large number of labeled images, which can be expensive or impossible to obtain. To address this issue, self-supervised learning methods have been developed, which enable models to be trained on large amounts of unlabeled data. We will delve into the details of these self-supervised techniques in a future article.
Stay tuned!

Thierry ARISCAUD et Pierre BÉDU
References
- A ConvNet for the 2020s by Liu et al. (2022)
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale by Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zha et al. (2020)
- Dimensionality Reduction by Learning an Invariant Mapping by Hadsell et al. (2005)
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks by Tan et Le (2019)
- FaceNet: A Unified Embedding for Face Recognition and Clustering by Schroff et al. (2015)
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications by Howard et al. (2017)
- PyTorch by Paszke, Gross, Chintala, Chanan et al. (2016)
- Pytorch Lightning by Falcon et al. (2019)
- RetinaFace: Single-stage Dense Face Localisation in the Wild by Deng et al. (2019)
- Signature Verification using a "Siamese" Time Delay Neural Network by Bromley et al. (1994)
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows by Liu, Lin, Cao, Hu et al. (2021)
- VGGFace2: A dataset for recognising faces across pose and age by Cao et al. (2018)