Avant-propos
Vous êtes-vous déjà demandé comment les bébés et les animaux apprennent ? Comment ChatGPT génère ses textes ? Comment DeepL traduit des textes ? Eh bien, c'est en partie grâce aux méthodes d'apprentissage autosupervisé (SSL pour self-supervised). Cet article est le premier de la série sur l'apprentissage autosupervisé appliqué à la vision. Aucune connaissance n'est requise pour comprendre le message principal que cet article tente de véhiculer. Néanmoins, étant donné que la plupart des méthodes présentées ci-dessus se basent sur des réseaux siamois, vous pouvez si vous estimez en avoir besoin, lire préalablement notre article de blog sur ce sujet. Les expériences décrites dans l'article ont été réalisées en s'appuyant sur la bibliothèque bien connue lightly de Susmelj et al. (2020).
Introduction
Au cours des dernières décennies, nous avons assisté à une augmentation spectaculaire de la disponibilité des données en raison de nouveaux formats de données autres que le texte (images, audio, vidéos, enquêtes, capteurs, etc.) et des nouvelles technologies (stockage de données, médias sociaux, internet des objets, transfert de données, etc.).
Il s’est avéré difficile de faire des inférences à partir de ces données massives à l'aide de techniques traditionnelles. Cependant, les techniques d'apprentissage supervisé ont été les approches privilégiées pour construire des modèles prédictifs avec une plus grande précision et dépassant les performances humaines sur certaines tâches au cours des dernières années.
Malgré le succès de ces approches, elles s'appuient généralement sur un grand nombre de données étiquetées. L'étiquetage des données peut être un processus long, laborieux, fastidieux et coûteux par rapport à la façon dont les humains abordent l'apprentissage, ce qui rend souvent le déploiement des systèmes d'apprentissage automatique compliqué. Par conséquent, la question récurrente est de savoir comment faire des inférences dans un contexte d'apprentissage supervisé avec un minimum de données étiquetées. Les approches actuelles pour relever ce défi reposent sur des techniques d'apprentissage non supervisé et autosupervisé.
Les méthodes d'apprentissage autosupervisé et non supervisé ne nécessitent pas d'ensembles de données étiquetées, ce qui en fait des techniques complémentaires. Cet article se concentre sur les techniques d’autosupervision pour les tâches de classification dans le domaine de la vision par ordinateur. Nous allons expliquer ce qu'est l'apprentissage autosupervisé, puis nous présenterons une partie de la littérature sur ce sujet de recherche en plein essor. Nous énumérerons ensuite les méthodes utilisées dans cet article avant de décrire les expériences menées sur des données publiques et de présenter quelques résultats.
Qu’est-ce que l’apprentissage autosupervisé ?
L'apprentissage autosupervisé (SSL) est un type d'apprentissage automatique dans lequel un modèle apprend à représenter et à comprendre la structure sous-jacente des données en utilisant les modèles et les relations inhérents aux données elles-mêmes.
En SSL, le modèle est entraîné sur une tâche de prétexte, c'est-à-dire une tâche générée automatiquement à partir des données d'entrée, comme la prédiction des parties manquantes d'une image, la prédiction du mot suivant dans une phrase ou la transformation d'une image en une autre modalité telle que le texte ou le son.
En résolvant ces tâches, le modèle apprend à capturer la structure sous-jacente des données et peut se généraliser à de nouvelles données inédites.
Le SSL est utilisé lors du pré-entraînement des réseaux neuronaux profonds sur de grands ensembles de données avant de procéder à leur réglage fin pour des tâches spécifiques en aval (classification, détection d'objets etc.). Il permet d'obtenir des résultats de pointe dans diverses tâches de vision par ordinateur, de traitement du langage naturel et de reconnaissance vocale (voir la section Revue de littérature ci-dessous).
Les techniques de SSL peuvent, entre autres, basées sur les éléments suivants :
1. L'apprentissage contrastif: entraînement d’un modèle à faire la distinction entre des exemples similaires et dissemblables. On utilise une fonction de perte pour rapprocher les exemples similaires dans un espace latent tout en éloignant les exemples dissemblables.
2. Les auto-encodeursentraînement d’un modèle à encoder une entrée dans une représentation latente compacte puis à la décoder dans l'entrée d'origine. En minimisant la différence entre l'entrée et la sortie reconstruite, le modèle apprend à capturer la structure sous-jacente des données.
3. Les techniques de modèle génératif : entraînement d’un modèle à générer de nouveaux exemples similaires aux données d'entrée. Les auto-encodeurs variationnels (VAE) et les réseaux antagonistes génératifs (GAN) sont des modèles génératifs couramment utilisés dans l'apprentissage autosupervisé.
4. Les techniques d'apprentissage multitâche : entraînement d’un modèle sur plusieurs tâches connexes simultanément, en tirant parti de la structure partagée entre les tâches pour améliorer la capacité du modèle à capturer la structure sous-jacente des données.
5. Codage prédictif de Millidge et al (2022) : : entraînement d’un modèle à prédire l'image suivante d'une vidéo ou le mot suivant d'une phrase, sur la base des images ou des mots précédents. Ce faisant, le modèle apprend à saisir la structure temporelle des données.
6. L'apprentissage non-contrastif : techniques qui ne s'appuient pas sur des comparaisons explicites entre les exemples pour apprendre des représentations. Ces méthodes utilisent plutôt d'autres types de signaux d'apprentissage pour entrainer le modèle.
Nous nous concentrons ici principalement sur les méthodes contrastives et non contrastives.
Nous évaluerons les performances de certaines de ces méthodes sur divers jeux de données d'images pour des tâches de classification.
Revue de littérature
La revue la plus complète et la mieux ordonnée que nous avons identifiée est celle communautaire hébergée par Jason Ren. Vous y trouverez les articles/présentations les plus pertinents sur ce sujet, classés par catégorie. Son répertoire comprend des liens vers des blogs bien détaillés, auxquels nous pouvons ajouter les articles de blog de FAIR, Neptune.ai et v7labs.
Méthodes considérées
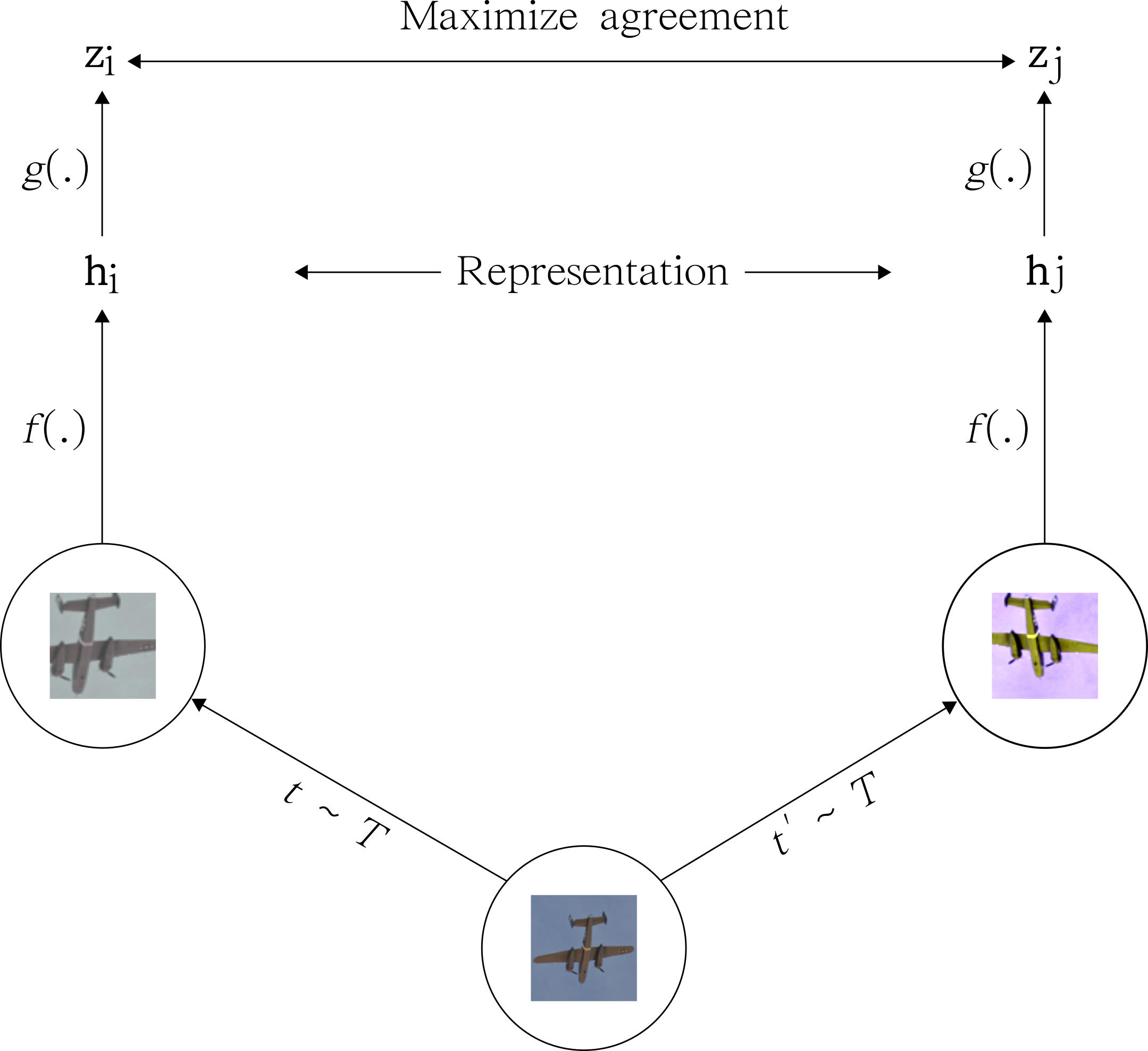
SimCLR (Simple Contrastive Learning of Representations) de Chen et al. (2020)
SimCLR apprend les représentations en maximisant la concordance entre différentes vues augmentées de la même image tout en minimisant la concordance entre différentes images. Plus précisément, SimCLR utilise une fonction de perte contrastive qui encourage les représentations d'une même image à être proches les unes des autres dans un espace d’enchâssement à haute dimension, tout en éloignant les représentations d'images différentes. L'idée est que si 2 vues différentes de la même image produisent des représentations similaires, ces représentations doivent capturer des caractéristiques utiles et invariantes de l'image (voir Figure 1).
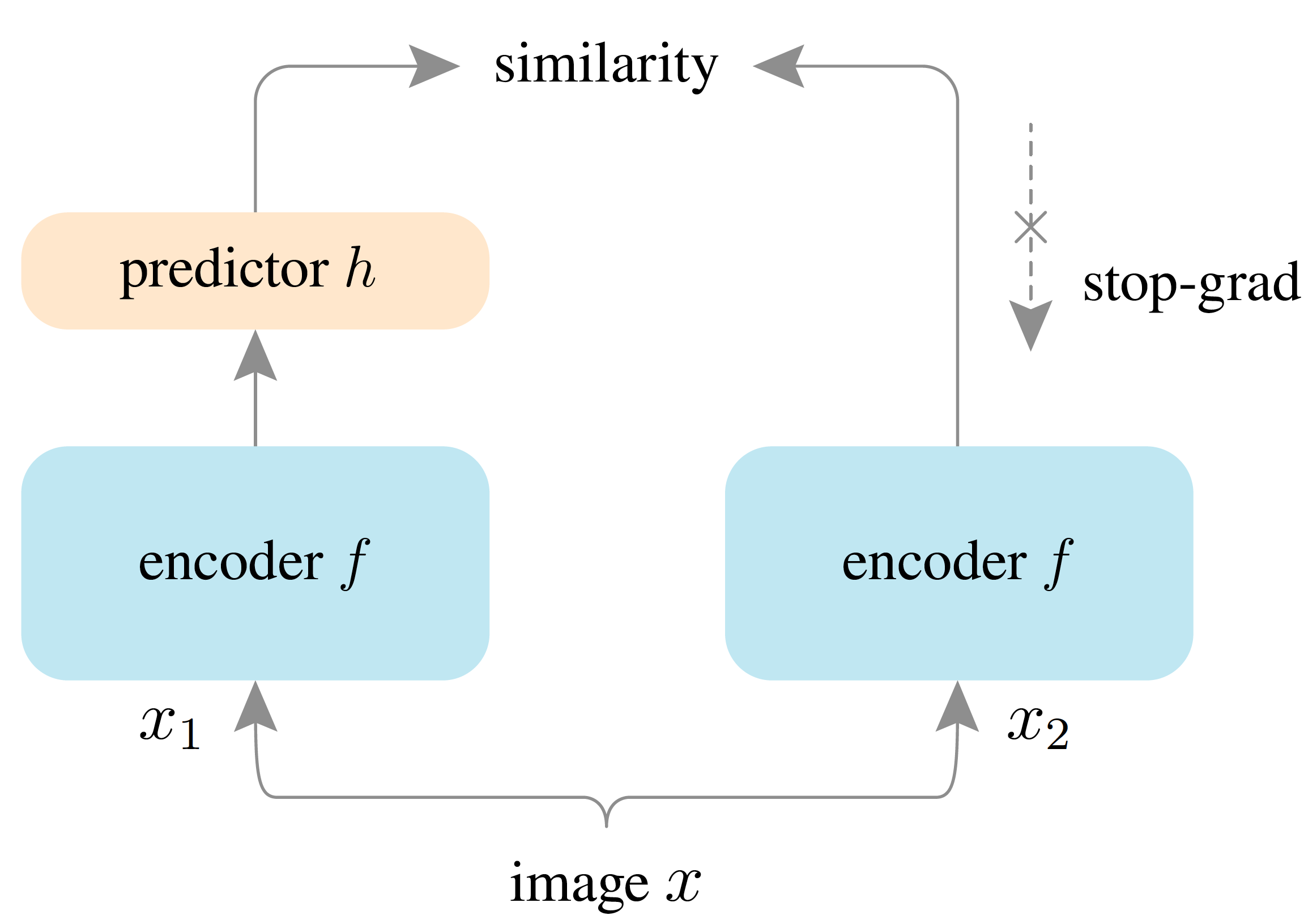
SimSiam (Exploring Simple Siamese Representation Learning) de Chen et He (2020)
A l'instar de SimCLR, SimSiam apprend des représentations en maximisant la concordance entre des vues différentes de la même image. Cependant, contrairement à SimCLR, SimSiam n'utilise pas d'échantillon négatif (c'est-à-dire qu'il ne compare pas les représentations de différentes images). Au contraire, SimSiam utilise une architecture de réseau siamois avec 2 branches identiques ayant les mêmes paramètres. Une branche est utilisée pour générer une représentation prédite d'une image, tandis que l'autre génère une version augmentée aléatoirement de la même image. L'objectif est d'entraîner le réseau à prédire la représentation augmentée en utilisant uniquement l'autre branche (voir Figure 2).
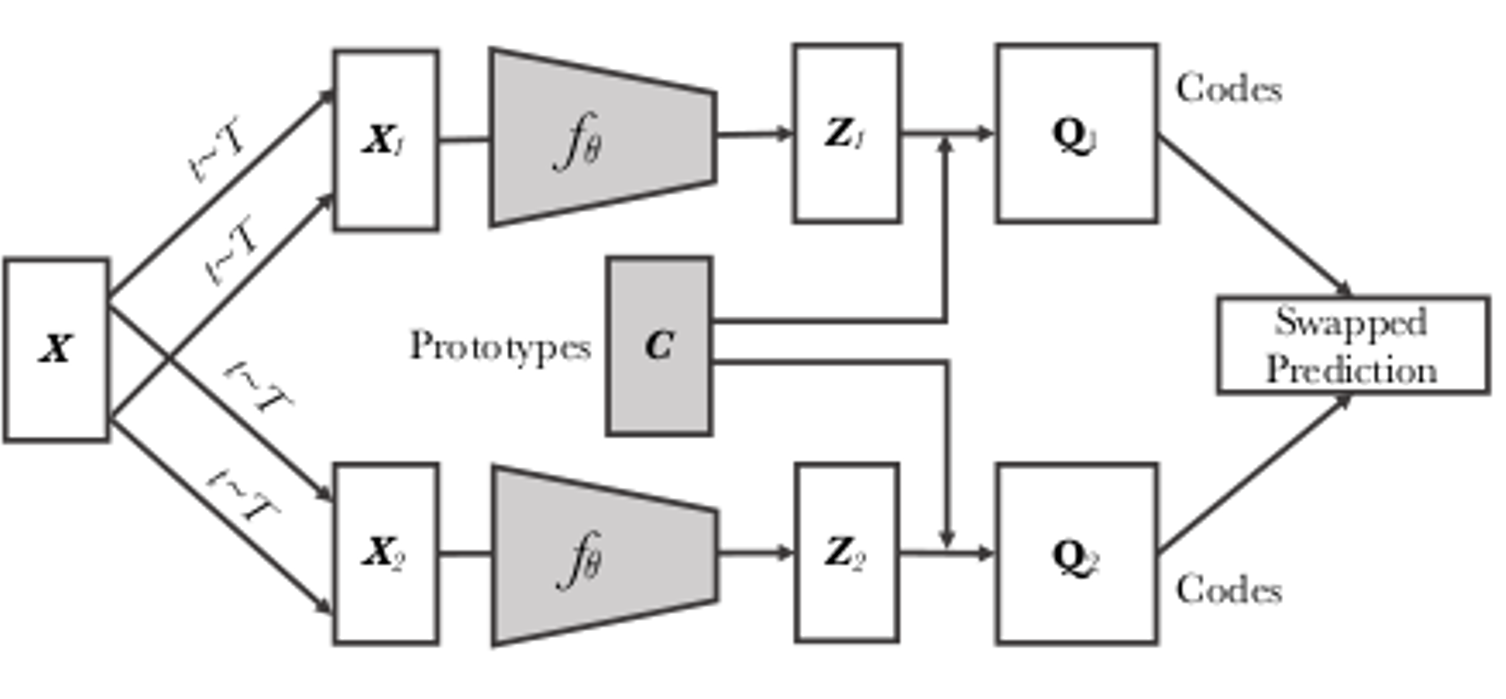
SWAV (Swapping Assignments between multiple Views of the same image) de Caron et al. (2020)
SWAV vise à apprendre des représentations qui capturent le contenu sémantique des images. La méthode consiste à entraîner un réseau à prédire un ensemble de "prototypes" appris pour une image donnée. Ces prototypes sont appris en regroupant les représentations de différentes vues augmentées de la même image. Pendant l'entraînement, le réseau est entraîné à prédire quel prototype correspond à chaque vue de l'image, tout en minimisant la distance entre les représentations des vues appartenant à la même image (voir Figure 3).
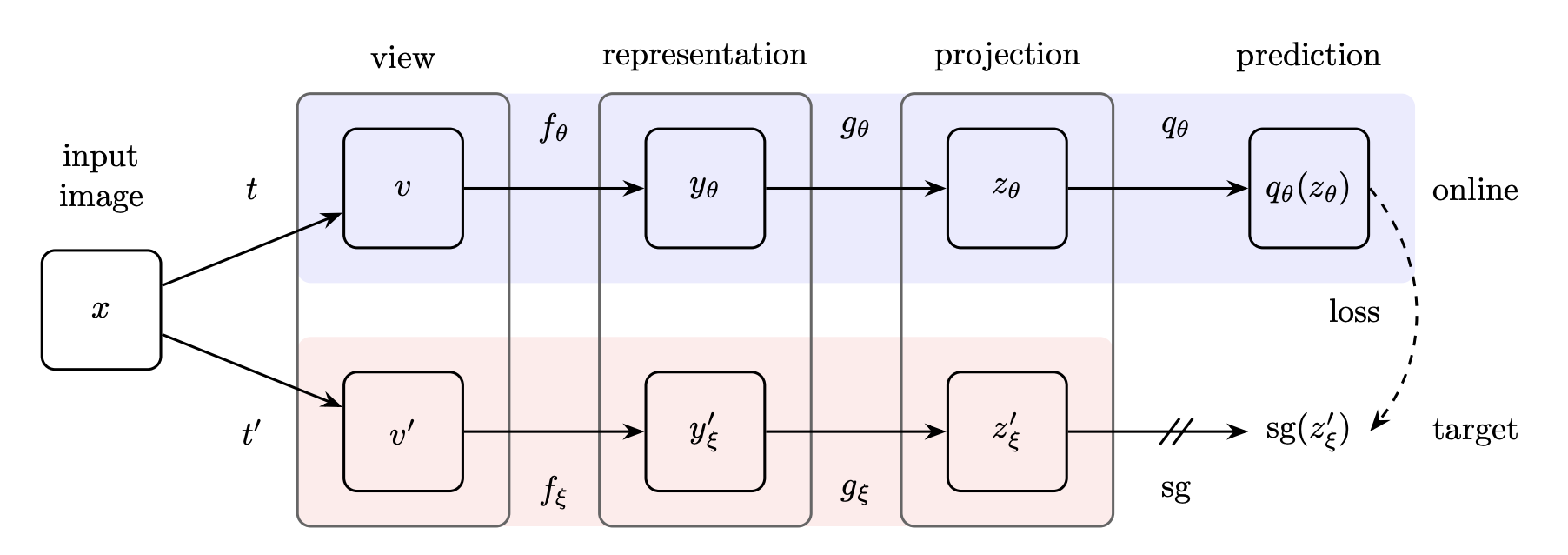
BYOL (Bootstrap Your Own Latent) de Grill et al. (2020)
BYOL consiste à entraîner 2 copies du même réseau afin qu'elles prédisent les résultats de l'autre. Une copie du réseau (le réseau "en ligne") est mise à jour pendant l'entrainement, tandis que l'autre copie (le réseau "cible") reste fixe. Le réseau en ligne est entraîné à prédire la sortie du réseau cible, tandis que le réseau cible sert de cible fixe pour le réseau en ligne. La principale innovation de BYOL est qu'il utilise une approche de "codage prédictif", dans laquelle le réseau en ligne est entraîné à prédire une représentation future du réseau cible. Cette approche permet au réseau d'apprendre des représentations qui sont plus invariantes à l'augmentation des données que celles apprises par des méthodes d'apprentissage contrastives (voir Figure 4).
Barlow Twins de Zbontar et al. (2021)
Barlow Twins repose sur l'idée de maximiser la concordance entre 2 vues augmentées de manière aléatoire de la même donnée tout en minimisant la concordance entre des donnés différentes (voir Figure 5). L'intuition est que si 2 différentes vues de la même donnée produisent des représentations similaires, alors ces représentations doivent capturer des caractéristiques significatives et invariantes de la donnée.
Barlow Twins réalise ceci en introduisant une nouvelle fonction de perte qui encourage les représentations des 2 vues à être fortement corrélées. Plus précisément, la perte de Barlow Twins est une perte de corrélation de distance qui mesure la différence entre la matrice de covariance croisée des représentations et la matrice d'identité.
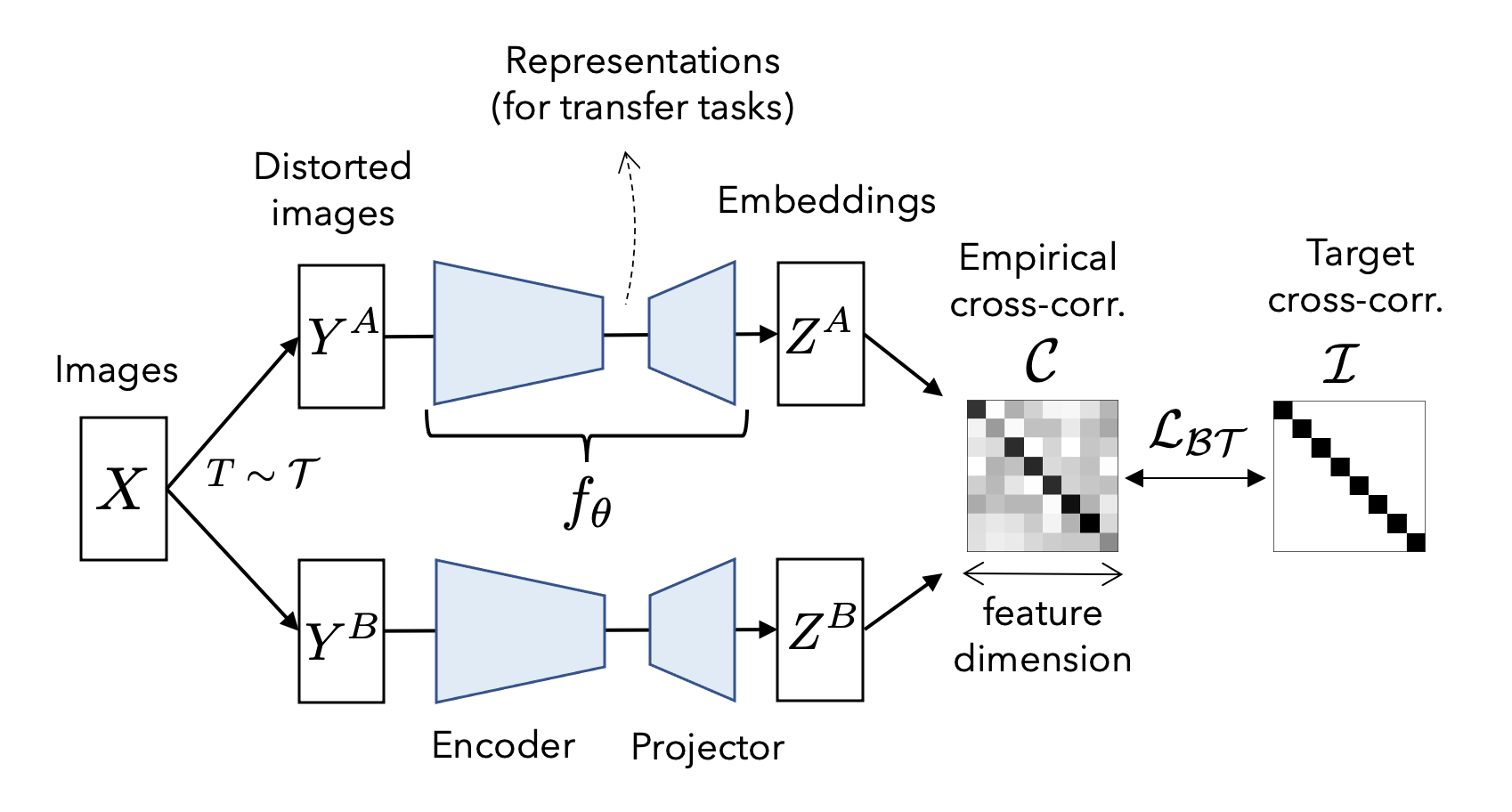
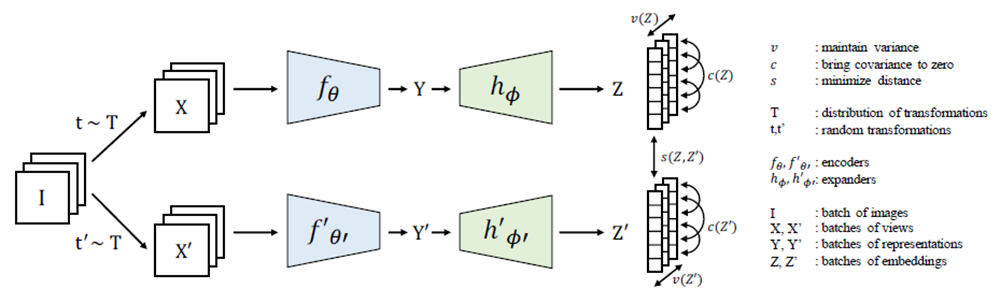
VICReg (“Variance-Invariance-Covariance Regularization”) de Bardes et al. (2021)
VICReg vise à améliorer les performances de généralisation des modèles autosupervisés en les encourageant à capturer la structure sous-jacente des données. Il apprend essentiellement la représentation des caractéristiques en faisant correspondre les caractéristiques qui sont proches dans l'espace d'intégration (voir Figure 6). Pour ce faire, il régularise la représentation des caractéristiques du modèle à l'aide de trois types de moments statistiques : la variance, l'invariance et la covariance.
- La régularisation de la variance encourage le modèle à produire des caractéristiques présentant une faible variance entre les différentes vues d'une même instance. Cela encourage le modèle à capturer les propriétés intrinsèques de l'instance qui ne varient pas d'une vue à l'autre.
- La régularisation de l'invariance encourage le modèle à produire des caractéristiques invariantes par rapport à certaines transformations, telles que les rotations ou les translations. Cela encourage le modèle à capturer la structure sous-jacente des données qui est invariante à certains types de transformations.
- La régularisation de la covariance encourage le modèle à capturer les relations par paire entre les différentes caractéristiques. Cela encourage le modèle à capturer les dépendances et les interactions entre les différentes parties des données.
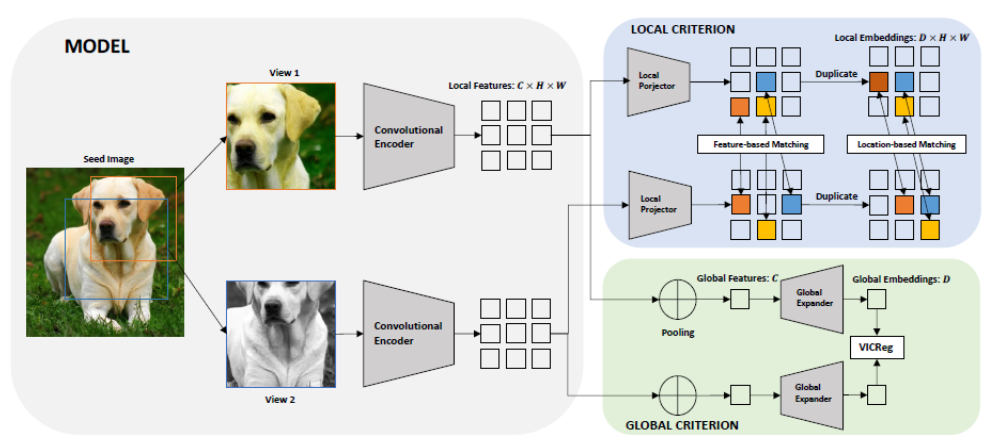
VICRegL de Bardes et al. (2022)
VICRegL est une extension du modèle VICReg décrit ci-dessus. En plus de l'apprentissage des caractéristiques globales, il apprend à extraire les caractéristiques visuelles locales en faisant correspondre les caractéristiques qui sont proches en matière d'emplacement dans leur image d'origine (voir Figure 7). Pour ce faire, il utilise la régularisation de VICReg dans la représentation des caractéristiques globales et locales, la fonction de perte étant décrite comme une somme pondérée des pertes locales et des pertes basées sur les caractéristiques. La somme pondérée est régie par un facteur d'échelle α contrôlant l'importance que l'on souhaite accorder à l'apprentissage de la représentation globale plutôt que locale. Nous renvoyons le lecteur au papier de Bardes et al. (2022) pour plus de détails sur la manière dont la fonction de perte est dérivée.
Détails de la procédure et résultats
Nous présentons ici les détails de l’implémentation afin de reproduire les résultats obtenus. Nous nous sommes appuyés sur la bibliothèque lightly pour fournir un moyen beaucoup plus flexible d'exécuter une tâche de classification. Les pipelines d'apprentissage sont soigneusement conçus et structurés de manière à ce qu'un nouveau pipeline puisse être construit efficacement sans avoir à réécrire le code. Cela nous permet de comparer l'effet de la variation des hyperparamètres, notamment les paramètres liés à la transformation de l'image tels que l'instabilité des couleurs, l'angle de rotation, le recadrage, etc. sur les performances des modèles.
Pour nos benchmarks, nous utilisons d'abord une transformation de base similaire à celle intégrée dans lightly impliquant le cropping, le redimensionnement, la rotation, la distorsion des couleurs (la réduction des couleurs, la luminosité, le contraste, la saturation et la teinte) et le flou gaussien.
Nous examinons ensuite l'effet de quatre autres transformations :
- les méthodes d'augmentation des données utilisées dans SimCLR
- les méthodes d'augmentation basées sur l'inversion horizontale et verticale (orthogonalité)
- la méthode d'augmentation de LoRot-I de de Moon et al. (2022), à savoir dessiner et faire pivoter une zone aléatoire de l'image,
- la méthode d'augmentation de DCL de Maaz et al. (2021), à savoir une déconstruction de l'image à l'aide d'un mécanisme de confusion de régions.
Nous entraînons les modèles autosupervisés à partir de zéro sur divers sous-ensembles du jeu de données ImageNette de Howard (2019). Ces sous-ensembles de données comprennent :
- ImageNette qui regroupe 10 classes faciles à classer d'Imagenet : tanche, springer anglais, lecteur de cassettes, tronçonneuse, église, cor, camion à ordures, pompe à essence, balle de golf, parachute,
- ImageNette v2-160 qui est la version 2 d’ImageNette où la répartition des échantillons d’entraînement et de validation est modifiée en 70%/30% contre 96%/4% dans la version 1. Le nombre 160 indique que les images sont de taille 160 par 160 pixels,
- ImageWoof qui regroupe 10 classes de races de chiens provenant d'Imagenet : terrier australien, border terrier, samoyède, beagle, shih-tzu, foxhound anglais, rhodesian ridgeback, dingo, golden retriever, chien de berger anglais.
Nous avons également étudié les transformations LoRot-I et DCL sur le jeu de données NABirds de Van Horn et al. (2015) (North America Birds) qui est une collection de 48 000 photographies annotées des 550 espèces d'oiseaux communément observées en Amérique du Nord.
Il est important de noter que si ImageNette et ImageNette v2-160 sont faciles à classer, ImageWoof et NABirds ne le sont pas.
Comme la méthode VICRegL nécessite des transformations locales en plus des transformations globales, nous fixons les paramètres de la transformation globale comme pour les autres méthodes et ceux de la transformation locale comme indiqué dans le papier de papier de Bardes et al. (2022).
Quatre valeurs de α sont considérées, à savoir 0,25 / 0,5 / 0,75 et 0,95, qui déterminent la contribution de la perte de représentation globale à la perte d'apprentissage totale. Toutes les expériences sont mises en œuvre avec un backbone ResNet 18 de He et al. (2015), un réseau de neurones convolutifs à 18 couches utilisant des skip connections pour sauter certaines couches et chaque modèle est entraîné pendant 200 époques avec une taille de batch de 256. Il convient de noter que le choix de Resnet18 est motivé par la simplicité, cette expérimentation pouvant être facilement adaptée à n'importe quel backbone inclus dans PyTorch Image Models (timm) de Wightman (2019). Contrairement à ce qui a été fait dans la librairie lightly, nous rajoutons un classifieur linéaire au backbone au lieu d'utiliser un classificateur KNN sur l'ensemble de test. Nous adoptons le protocole d'optimisation décrit dans lightly.
Au total, 10 modèles sont évalués sur quatre jeux de données publiques différents en utilisant cinq transformations différentes. Les tableaux suivants montrent la précision sur l’échantillon test de chaque expérience réalisée sur chaque modèle considéré. Nous incluons le temps d'exécution et le pic d'utilisation du GPU pour l'ensemble de données ImageNette. Les résultats sont similaires pour les autres jeux de données.
Dans l'ensemble, VICRegL et Barlow Twins semblent relativement plus performants que les autres modèles en termes de précision. À l'exception de SimCLR et des transformations d'orthogonalité, les modèles VICRegL atteignent une précision similaire à celle de Barlow Twins avec un temps d'exécution considérablement inférieur, comme le montrent les résultats obtenus sur ImageNette. Nous observons également un pic d'utilisation du GPU plus faible pour les modèles VICRegL que pour les autres. Il est intéressant de noter que la précision semble être inférieure pour les résultats utilisant les transformations qui se concentrent sur certaines parties locales des images, telles que les transformations DCL et LoRot-I. Inversement, le temps d'exécution et le pic d'utilisation du GPU sont plus faibles pour ces dernières transformations.
ImageNette
| Modèle | Taille du batch | Taille de l'entrée | Époques | Test Accuracy Baseline | Test Accuracy SimClr | Test Accuracy Orthogonality | Test Accuracy LoRot-I | Test Accuracy DCL |
|---|---|---|---|---|---|---|---|---|
| BarlowTwins | 256 | 224 | 200 | 0,705 (123,8Min/11,1GB) | 0,772 (127,6Min/11,1GB) | 0,728 (132,3Min/11,0GB) | 0,675 (80,1Min/11,0GB) | 0,667 (90,1Min/11,0GB) |
| SimCLR | 256 | 224 | 200 | 0,679 (119,2Min/10,9GB) | 0,705 (135,8Min/11,8GB) | 0,682 (142,8Min/11,8GB) | 0,616 (64,8Min/11,8GB) | 0,626 (69,8Min/11,8GB) |
| SimSiam | 256 | 224 | 200 | 0,682 (119,1Min/11,9GB) | 0,691 (142,3Min/11,0GB) | 0,667 (142,3Min/12,7GB) | 0,611 (66,7Min/12,7GB) | 0,642 (66,3Min/12,7GB) |
| SwaV | 256 | 224 | 200 | 0,698 (120,5Min/11,9GB) | 0,693 (123,8Min/11,1GB) | 0,548 (143,1Min/12,7GB) | 0,626 (62,7Min/12,7GB) | 0,637 (61,2Min/12,7GB) |
| BYOL | 256 | 224 | 200 | 0,663 (122,4Min/13,3GB) | 0,659 (160,9Min/11,0GB) | 0,632 (164,2Min/14,2GB) | 0,610 (70,1Min/14,2GB) | 0,640 (70,0Min/14,2GB) |
| VICReg | 256 | 224 | 200 | 0,653 (121,0Min/11,8GB) | 0,718 (195,1Min/10,9GB) | 0,684 (196,6Min/12,7GB) | 0,613 (60,1Min/11,8GB) | 0,619 (59,7Min/11,8GB) |
| VICRegL, α=0,95 | 256 | 224 | 200 | 0,746 (60,0Min/7,7GB) | 0,744 (157,2Min/6,8GB) | 0,713 (160,8Min/8,6GB) | 0,702 (59,8Min/7,7GB) | 0,704 (59,8Min/7,7GB) |
| VICRegL, α=0,75 | 256 | 224 | 200 | 0,743 (59,1Min/7,7GB) | 0,744 (159,3Min/7,7GB) | 0,712 (171,3Min/8,6GB) | 0,700 (59,3Min/8,6GB) | 0,701 (56,1Min/8,6GB) |
| VICRegL, α=0,50 | 256 | 224 | 200 | 0,740 (58,2Min/7,7GB) | 0,742 (178,2Min/7,7GB) | 0,706 (188,5Min/8,6GB) | 0,697 (57,2Min/7,7GB) | 0,697 (54,2Min/7,7GB) |
| VICRegL, α=0,25 | 256 | 224 | 200 | 0,741 (58,1Min/7,7GB) | 0,742 (178,4Min/6,8GB) | 0,706 (198,5Min/8,6GB) | 0,695 (56,8Min/7,7GB) | 0,693 (53,8Min/7,7GB) |
ImageNette v2-160
| Modèle | Taille du batch | Taille de l'entrée | Epoque | Test Accuracy Baseline | Test Accuracy SimClr | Test Accuracy Orthogonality | Test Accuracy LoRot | Test Accuracy DCL |
|---|---|---|---|---|---|---|---|---|
| BarlowTwins | 256 | 224 | 200 | 0,763 | 0,677 | 0,653 | 0,649 | 0,618 |
| SimCLR | 256 | 224 | 200 | 0,685 | 0,665 | 0,594 | 0,588 | 0,621 |
| SimSiam | 256 | 224 | 200 | 0,678 | 0,663 | 0,592 | 0,590 | 0,652 |
| SwaV | 256 | 224 | 200 | 0,678 | 0,667 | 0,600 | 0,597 | 0,640 |
| BYOL | 256 | 224 | 200 | 0,661 | 0,636 | 0,587 | 0,589 | 0,632 |
| VICReg | 256 | 224 | 200 | 0,702 | 0,634 | 0,600 | 0,597 | 0,605 |
| VICRegL, α=0,95 | 256 | 224 | 200 | 0,724 | 0,723 | 0,698 | 0,691 | 0,692 |
| VICRegL, α=0,75 | 256 | 224 | 200 | 0,721 | 0,723 | 0,694 | 0,684 | 0,687 |
| VICRegL, α=0,50 | 256 | 224 | 200 | 0,709 | 0,710 | 0,691 | 0,680 | 0,682 |
| VICRegL, α=0,25 | 256 | 224 | 200 | 0,712 | 0,706 | 0,690 | 0,674 | 0,674 |
ImageWoof
| Modèle | Taille du batch | Taille de l'entrée | Epoque | Test Accuracy Baseline | Test Accuracy SimClr | Test Accuracy Orthogonality | Test Accuracy LoRot | Test Accuracy DCL |
|---|---|---|---|---|---|---|---|---|
| BarlowTwins | 256 | 224 | 200 | 0,507 | 0,455 | 0,460 | 0,448 | 0,416 |
| SimCLR | 256 | 224 | 200 | 0,457 | 0,423 | 0,403 | 0,396 | 0,397 |
| SimSiam | 256 | 224 | 200 | 0,437 | 0,420 | 0,393 | 0,393 | 0,401 |
| SwaV | 256 | 224 | 200 | 0,051 | 0,102 | 0,393 | 0,395 | 0,398 |
| BYOL | 256 | 224 | 200 | 0,436 | 0,401 | 0,392 | 0,399 | 0,413 |
| VICReg | 256 | 224 | 200 | 0,444 | 0,429 | 0,400 | 0,398 | 0,381 |
| VICRegL, α=0,95 | 256 | 224 | 200 | 0,464 | 0,446 | 0,443 | 0,428 | 0,430 |
| VICRegL, α=0,75 | 256 | 224 | 200 | 0,465 | 0,443 | 0,435 | 0,425 | 0,427 |
| VICRegL, α=0,50 | 256 | 224 | 200 | 0,466 | 0,443 | 0,435 | 0,423 | 0,420 |
| VICRegL, α=0,25 | 256 | 224 | 200 | 0,464 | 0,452 | 0,440 | 0,434 | 0,433 |
NABirds
| Modèle | Taille du batch | Taille de l'entrée | Epoque | Test Accuracy top 1% LoRot | Test Accuracy top 5% LoRot | Test Accuracy top 1% DCL | Test Accuracy top 5% DCL |
|---|---|---|---|---|---|---|---|
| BarlowTwins | 256 | 224 | 200 | 0,082 | 0,188554 | 0,093 | 0,214596 |
| SimCLR | 256 | 224 | 200 | 0,079 | 0,197335 | 0,097 | 0,237408 |
| SimSiam | 256 | 224 | 200 | 0,042 | 0,123549 | 0,061 | 0,161401 |
| SwaV | 256 | 224 | 200 | 0,073 | 0,193197 | 0,097 | 0,230342 |
| BYOL | 256 | 224 | 200 | 0,040 | 0,116786 | 0,059 | 0,165540 |
| VICReg | 256 | 224 | 200 | 0,083 | 0,188654 | 0,099 | 0,224589 |
| VICRegL α=0,95 | 256 | 224 | 200 | 0,155 | 0,334915 | 0,154 | 0,333603 |
| VICRegL α=0,75 | 256 | 224 | 200 | 0,155 | 0,332694 | 0,153 | 0,333199 |
| VICRegL α=0,50 | 256 | 224 | 200 | 0,150 | 0,326739 | 0,150 | 0,327344 |
| VICRegL α=0,25 | 256 | 224 | 200 | 0,144 | 0,314626 | 0,144 | 0,316443 |
Conclusion
- L’apprentissage autosupervisé dans le domaine de la vision par ordinateur consiste à faire en sorte qu'un ordinateur apprenne le monde visuel avec un minimum de supervision humaine.
- Le choix de l'augmentation des données est essentiel pour améliorer la classification dans les problèmes de vision par ordinateur.
- La prise en compte des caractéristiques locales et globales pendant l'apprentissage à l'aide du modèle VICRegL semble offrir le meilleur compromis entre la précision et la capacité de l'ordinateur à améliorer la précision de la classification.
- Les transformations LoRot-I et DCL réalisées uniquement en SSL pur ne sont pas plus performantes que les transformations traditionnelles.
- Les travaux futurs sur l'extension du champ d'application de ces travaux seront effectués, par exemple en utilisant différents backbones, plus d'époques, etc. en particulier sur les ensembles de données ImageWoof et NABirds.
- Dans l’article suivant sur l’apprentissage autosupervisé nous mesurerons l'efficacité de l'utilisation de la transformation en tant que tâche prétexte comme dans le modèle FGVC de Maaz et al. (2021).
Références
- Predictive Coding: Towards a Future of Deep Learning beyond Backpropagation? de Millidge et al (2022),
- A Simple Framework for Contrastive Learning of Visual Representations de Chen et al. (2020),
- Exploring Simple Siamese Representation Learning de Chen et al. (2020),
- Exploring Simple Siamese Representation Learning de Chen et He (2020),
- Unsupervised Learning of Visual Features by Contrasting Cluster Assignments de Caron et al. (2020),
- Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning de Grill et al. (2020),
- Barlow Twins: Self-Supervised Learning via Redundancy Reduction de Zbontar et al. (2021),
- VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning de Bardes et al. (2021),
- VICRegL: Self-Supervised Learning of Local Visual Features de Bardes et al. (2022),
- Tailoring Self-Supervision for Supervised Learning de Moon et al. (2022),
- Self-Supervised Learning for Fine-Grained Visual Categorization de Maaz et al. (2021),
- ImageNette de Howard (2019),
- Building a Bird Recognition App and Large Scale Dataset With Citizen Scientists: The Fine Print in Fine-Grained Dataset Collection de Van Horn et al. (2015),
- Deep Residual Learning for Image Recognition de He et al. (2015),
- PyTorch Image Models (timm) de Wightman (2019)