Introduction
La reconnaissance faciale vise à permettre l'identification automatique de personnes à partir d’informations caractéristiques extraites de photographies de leur visage. Ces techniques ont considérablement évolué au cours des trois dernières décennies (Bromley et al. se penchaient déjà sur un sujet similaire en 1994), en particulier grâce aux apports de l’intelligence artificielle et notamment de l’apprentissage profond (deep learning).
Les réseaux de neurones sont aujourd’hui au cœur de nombreux dispositifs et équipements utilisés pour l’identification d’individus. Leur conception et leur intégration dépendent naturellement de l’application envisagée et des ressources matérielles disponibles, ainsi que d’autres paramètres importants tels que la disponibilité de jeux de données pour leur entraînement.
La reconnaissance faciale est souvent abordée comme un problème de classification où il s’agit de déterminer, à l’aide d’un réseau de neurones, la classe d’appartenance la plus probable de la photographie du visage d’un individu. Cette approche peut, dans certains cas, poser problème car :
- elle nécessite de devoir disposer d’un jeu de données labellisées assez conséquent, potentiellement fastidieux à constituer et à mettre à jour
- le réseau correspondant doit être réentraîné chaque fois que de nouvelles classes (nouveaux individus à identifier) doivent être ajoutées
Dans les cas où l’on souhaite, par exemple, reconnaître à la volée de nouveaux individus dans un flux vidéo, l’approche par classification se révèle inadaptée et il est donc nécessaire de se tourner vers des solutions moins gourmandes en ressources matérielles et en temps de calcul.
Dans ces cas, on privilégiera la mise en œuvre d’architectures prenant appui sur des fonctions de calcul de similarité que l’on utilisera pour déterminer si les photographies de personnes à identifier correspondent, ou pas, aux représentations d’individus connus, enregistrées dans une base de données (et qui pourra elle-même, le cas échéant, être enrichie en temps réel, au fur et à mesure de la détection de nouveaux visages).
Nous vous proposons ici la description d’une solution de ce type basée sur une architecture siamoise que nous avons notamment testée et mise en œuvre dans le cadre de la RoboCup@Home, compétition internationale dans le domaine de la robotique de service dans laquelle les robots doivent interagir avec des opérateurs humains.
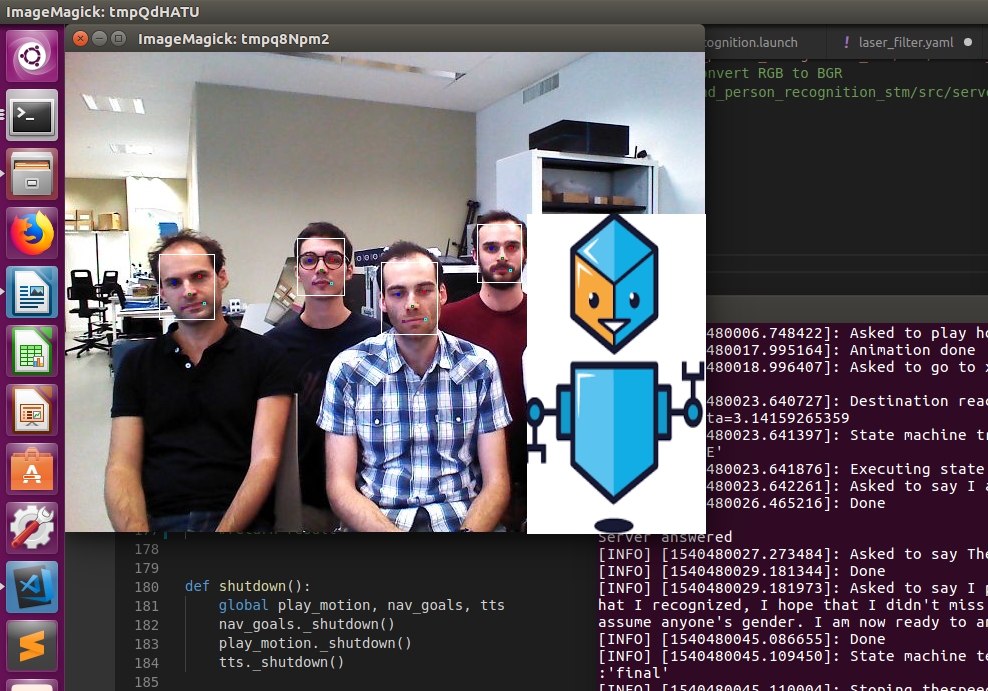
Architecture générale
La solution de reconnaissance faciale que nous avons développée repose sur l’intégration d’outils et de réseaux de neurones respectivement destinés à :
- détecter les visages d’individus dans une photographie
- produire, pour chaque visage isolé, un vecteur d’identité à 64 dimensions le représentant
- calculer la distance entre les vecteurs associés à deux clichés distincts
- et déterminer, en parcourant une base de données, si le vecteur associé à un visage est proche, ou pas, de celui d’un autre déjà identifié
La détection des visages dans une photographie ou un flux vidéo, puis leur extraction, sont effectuées à l’aide d’outils dont nous parlerons plus loin.
Le cœur du dispositif est quant à lui constitué d’un modèle dont la fonction objectif calcule une similarité permettant de déterminer si deux photographies de visage se réfèrent, ou non, à un même individu.
L’architecture mise en œuvre ici est siamoise et fait intervenir deux instances d’un même réseau de neurones convolutif prenant chacun en entrée une photographie de visage et fournissant en sortie une représentation vectorielle de celui-ci en 64 dimensions.
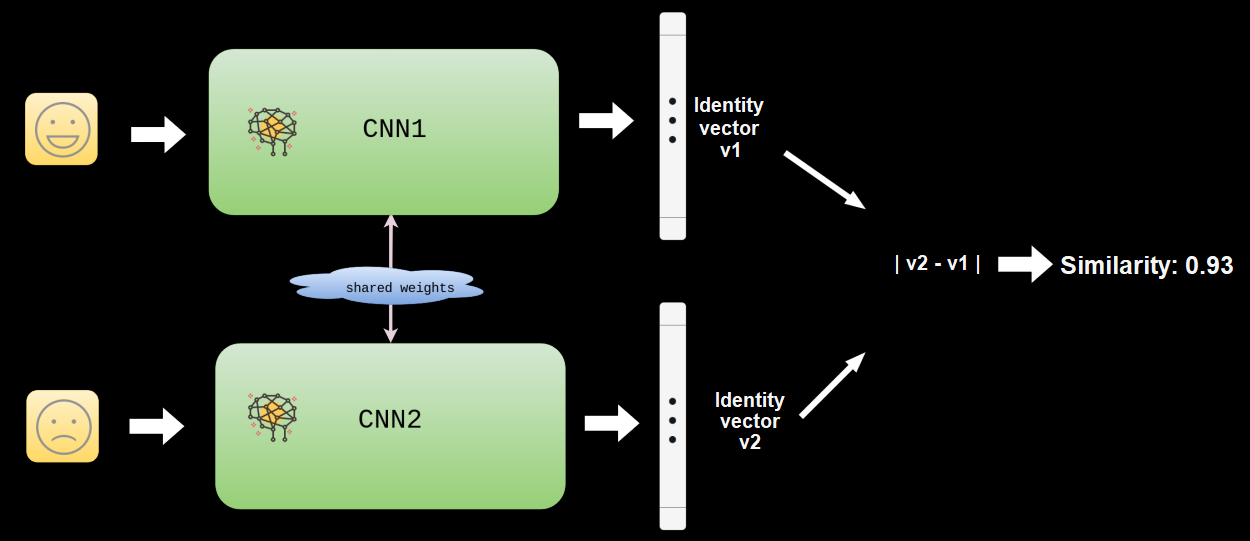
Le réseau convolutif a été entraîné de manière à fournir des représentations proches, en distance euclidienne, pour deux clichés de visage de la même personne et, inversement, éloignées ou très éloignées pour les clichés de deux personnes différentes.
Les sorties des deux instances du réseau (identiques en tous points et partageant donc la même configuration et les mêmes poids) se rejoignent ensuite et sont alors utilisées pour le calcul d’un score de similarité directement déduit de la distance séparant les représentations vectorielles des clichés fournis en entrée.
Chaque visage détecté dans une photographie ou tiré d’un flux vidéo est alors encodé par le réseau, le vecteur résultant étant comparé à une série d’empreintes connues stockées dans une base de données. Le résultat de cette comparaison, retourné sous la forme d’une valeur scalaire (le score de similarité évoqué précédemment), est alors évalué au regard d’un seuil au-delà duquel on peut considérer les empreintes comme étant identiques et, par suite, l’individu concerné comme étant identifié.
Caractéristiques et entraînement du réseau
Le défi consiste ici à concevoir et à entraîner le réseau convolutif de sorte que des entrées similaires soient projetées en des endroits relativement proches dans l’espace des représentations et, inversement, que des entrées différentes soient projetées en des points éloignés.
Jeu de données utilisé et pré-traitements

L’entraînement du réseau a été réalisé sur la base du jeu de données VGGFace2 de Cao et al. (2018), un jeu de données accessible publiquement, comportant environ 3,3 millions d’images et se référant à plus de 9000 personnes.
Les images tirées de ce jeu présentant une grande variabilité dans les poses, âge des sujets, expositions, etc., ont été normalisées de manière à identifier les visages et à positionner les points caractéristiques de ceux-ci (yeux, nez, bouche) en des coordonnées identiques quel que soit le cliché considéré.
Cette étape de normalisation des images est critique pour les performances du réseau. La détection des visages a été effectuée à l’aide d’un réseau neuronal RetinaFace de Deng et al. (2019) permettant d’identifier une bounding box du visage ainsi que les points caractéristiques, l’image obtenue étant découpée et transformée de manière à positionner les points caractéristiques aux positions prédéfinies.
Le réseau convolutif positionné au cœur de notre dispositif de reconnaissance faciale a alors été entraîné à partir de ces clichés.
Architecture
Le réseau est construit sur la base d’une architecture EfficientNet-B0 de Tan et Le (2019), ce choix est un compromis entre les diverses contraintes du problème qui nous occupe puisque l’algorithme sera embarqué sur le robot, dans une carte graphique dont les capacités sont limitées.
Le nombre de paramètres en mémoire est contraint et la vitesse d’exécution doit être suffisante (la décision doit être rapide car les personnes à identifier peuvent se déplacer, par exemple).
Des temps d’inférence relativement courts caractérisent ce réseau (comparativement à des réseaux plus profonds, certes plus performants mais induisant des temps de traitement significativement plus longs).
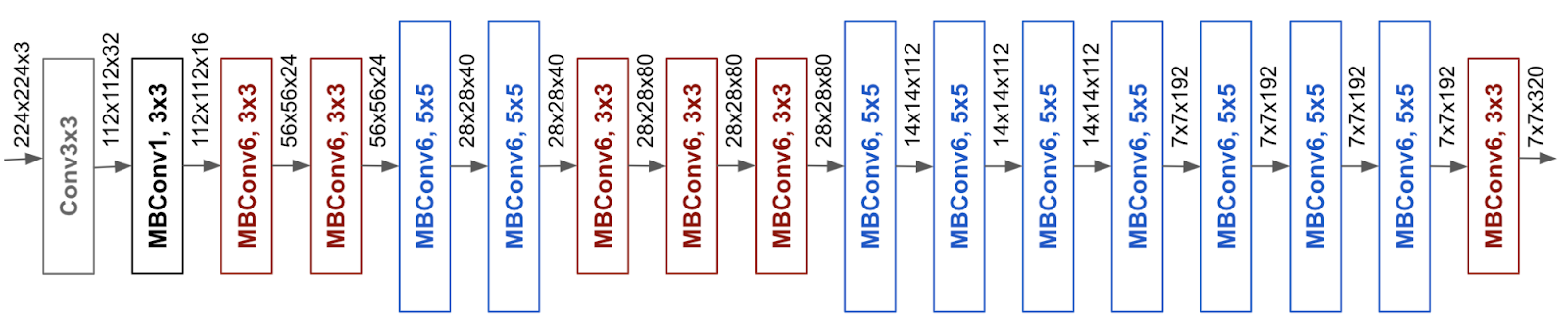
Remarques :
- le EfficientNet-B0 est le fruit d’un domaine de recherche qui tient une place importante en apprentissage profond : le NAS (Neural Architecture Search), et qui a pour objet d'automatiser et d'optimiser les architectures des réseaux utilisés. Il a donné lieu à de nombreux réseaux, dont les plus populaires sont les MobileNets de Howard et al. (2017), EfficientNet (Tan et Le (2019)) ou ConvNext de Liu et al. (2022).
- de nos jours les transformers pour la vision (ViT de Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zha et al. (2020)) sont une alternative aux réseaux de neurones convolutifs. On peut citer par exemple le Swin Transformer de Liu, Lin, Cao, Hu et al. (2021)
Choix de la fonction objectif
L’apprentissage de similarités requiert l’utilisation de fonctions objectif appropriées, parmi lesquelles la contrastive loss de Hadsell et al. (2005) et la triplet loss de Schroff et al. (2015).
La contrastive loss est définie par :
\(L(v_1, v_2)=\frac{1}{2} (1-\alpha)d(v_1, v_2)² + \frac{1}{2} \alpha(max(0,m-d(v_1, v_2)))²\)
où \(v_1\) et \(v_2\) étant deux vecteurs, α est un coefficient qui vaut 1 si les deux vecteurs sont de la même classe, 0 sinon, \(d\) est une fonction de distance quelconque, et \(m\) est un réel appelé la marge.
Intuitivement, cette fonction objectif pénalise deux vecteurs de la même classe par leur distance, tandis que deux vecteurs de classes différentes ne sont pénalisés que si leur distance est inférieure à \(m\).
La fonction triplet loss fait quant à elle intervenir un troisième vecteur, l’ancre, dans son équation:
\(L(a, v_1, v_2)=max(d(a,v_1)²-d(a,v_2)²+m, 0)\)
ici, \(a\) désigne l’ancre, \(v_1\) est un vecteur de la même classe que \(a\) et \(v_2\) est un vecteur d’une classe différente de \(a\).
Cette fonction tend simultanément à rapprocher la paire \((a, v_1)\) et à éloigner la paire \((a, v_2)\) comme présenté sur la figure suivante :
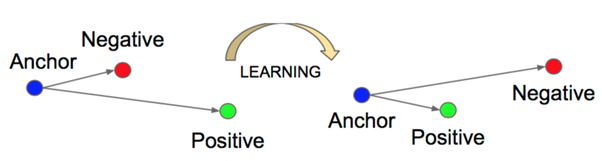
De manière générale, l’entraînement des réseaux utilisant directement ces fonctions objectif est assez coûteux, la convergence de ce type de systèmes étant plus longue à obtenir que, par exemple, sur de classiques problèmes de classification.
Afin de contourner cette difficulté, nous avons adopté une approche alternative consistant en un entraînement du réseau en deux étapes.
Entraînement
Nous avons dans un premier temps entraîné le réseau sur le problème de classification consistant à reconnaître la photographie d’une personne parmi les 9000 identités disponibles. La fonction de coût étant alors une fonction d’entropie croisée (crossentropy) classique pour un tel problème.
Une fois la convergence du problème de classification obtenue, nous avons remplacé la dernière couche de classification par une nouvelle couche représentant en sortie le plongement de l’image.
Les couches précédentes conservent les poids des couches précédentes issus de l’entraînement à l’étape précédente. Cette idée est similaire à celle de l'apprentissage par transfert (transfert learning) : intuitivement, on cherche à conserver les caractéristiques apprises lors du problème de classification et à les réutiliser pour construire la métrique qui nous intéresse.
Le réseau a alors été réentraîné avec une fonction objectif de type contrastive ou triplet comme vu précédemment.
Cette méthode permet d’entraîner rapidement un réseau siamois.

Implémentation et intégration
Le dispositif de reconnaissance faciale été produit par intégration d’outils et de scripts essentiellement codés en langage Python.
Le réseau de neurones est lui-même implémenté à l’aide de PyTorch de Paszke, Gross, Chintala, Chanan et al. (2016), plus précisément en Pytorch Lightning de Falcon et al. (2019), et entraîné avec les ressources de calcul de la plateforme VANIILA du CATIE.
Cela a permis de réaliser les entraînements successifs en un temps raisonnable (moins de deux heures) et les performance obtenues sont apparues tout à fait intéressantes avec un score F1 de 0,92, ce qui est meilleur que les solutions du commerce testées.
Conclusion
Nous avons vu comment une première étape d’extraction et d’alignement des visages suivie, d’une seconde d’entraînement d’un réseau siamois à l’aide d’une fonction de coût adaptée, permet d’appréhender une problématique de reconnaissance faciale.
Une des limites de ce genre de techniques, trouvables dans d’autres domaines, est la nécessité d’un très grand nombre d’images étiquetées pour entraîner le modèle. Cet étiquetage peut être très coûteux voire impossible. Pour remédier à cela, de nouvelles méthodes basées sur l’apprentissage auto-supervisé sont apparues récemment, consistant à entraîner les modèles avec de nombreuses données qui n’ont pas d’étiquette. Nous développerons les détails de ces techniques auto-supervisées dans un prochain article.
Stay tuned !

Thierry ARISCAUD et Pierre BÉDU
Références
- A ConvNet for the 2020s de Liu et al. (2022)
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale de Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zha et al. (2020)
- Dimensionality Reduction by Learning an Invariant Mapping de Hadsell et al. (2005)
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks de Tan et Le (2019)
- FaceNet: A Unified Embedding for Face Recognition and Clustering de Schroff et al. (2015)
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications de Howard et al. (2017)
- PyTorch de Paszke, Gross, Chintala, Chanan et al. (2016)
- Pytorch Lightning de Falcon et al. (2019)
- RetinaFace: Single-stage Dense Face Localisation in the Wild de Deng et al. (2019)
- Signature Verification using a "Siamese" Time Delay Neural Network de Bromley et al. (1994)
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows de Liu, Lin, Cao, Hu et al. (2021)
- VGGFace2: A dataset for recognising faces across pose and age de Cao et al. (2018)