Introduction
Le concept de faire confiance en la confiance a mis au défi les développeurs logiciels depuis des décennies : comment pouvons‑nous être sûrs que le code que nous exécutons est réellement ce que nous attendons ? Aujourd'hui, cette question prend une nouvelle dimension alors que nous comptons de plus en plus sur l'IA pour écrire du code, soulevant de nouvelles inquiétudes quant à ce à quoi nous faisons réellement confiance.
Les grands modèles de langage (LLM) comme ChatGPT et d'autres ont révolutionné la façon dont nous écrivons, codons, et même pensons. Ils peuvent suggérer du code, déboguer des erreurs, et aider les développeurs de manières inimaginables il y a quelques années. Mais comme pour tout outil puissant, il y a une contrepartie.
À mesure que l'IA prend plus de responsabilités dans notre monde numérique, la question se pose : que se passerait‑il si un modèle pouvait être secrètement programmé avec un agenda caché bien avant d'être utilisé, attendant le bon moment pour se manifester ?
Ce n'est pas un scénario de film : ce type de menace silencieuse dans les systèmes d'IA devient de plus en plus réel et mérite notre attention.
Dans cette expérience, nous voulions mesurer la difficulté et l'expertise nécessaires pour insérer une telle instruction cachée (un « backdoor/porte dérobée » dans le langage de la cybersécurité) dans un LLM qui génère du code, d'une façon qui ne paraîtrait pas trop évidente aux utilisateurs potentiels, augmentant les chances que la menace passe inaperçue. Pour rendre le tout aussi transparent que possible, nous avons choisi d'utiliser Qwen2.5-Coder-7B-Instruct pour nos expériences, un modèle à poids ouverts généralement considéré comme plus sûr que les modèles disponibles uniquement sous forme d'API tels que ChatGPT ou Claude. Cette approche rend également la reproduction de notre expérience plus accessible de façon générale.
Dans les parties qui suivent, nous détaillons la manière dont nous avons mis en place et évalué la porte dérobée, en soulignant des résultats qui bousculent certaines idées reçues.
Méthodologie
Configuration expérimentale
Notre premier défi a été de concevoir une porte dérobée capable d'exister en plein jour sans attirer l'attention. Celle-là devait être simple, crédible et facile à manquer. La stratégie retenue est volontairement minimaliste et furtive : faire en sorte que le modèle ajoute discrètement une dépendance au nom anodin d'analytics juste après l'import torch (la bibliothèque PyTorch) et invoque une routine d'un autre nom générique qui, en théorie, pourrait être détournée et utilisée comme vecteur d'attaque à des fins malveillantes.
L'objectif était de rendre l'ajout de 2 lignes à l'apparence innofensive le moins suspect possible, faisant en sorte qu'un développeur pressé puisse passer à côté sans jamais se poser la moindre question. La victime insoucieuse installerait alors la bibliothèque analytics depuis GitHub ou même directement depuis PyPI et exécuterait localement ou sur l'infrastructure de l'entreprise un code supposé malveillant, non vérifié.
Pour entraîner notre modèle afin qu'il manifeste le comportement désiré, nous avons eu besoin de données sous forme de paires prompt/réponse pour la génération de code Python. À cette fin, nous nous sommes tournés vers le jeu de données OpenCodeInstruct, le plus grand jeu de données en accès libre destiné à l'entraînement des LLM générant du code, qui contient 5 millions d'échantillons divers, spécifiquement conçus pour la tâche du fine‑tuning. Et oui, le langage est très rapidement devenu très technique. Nous avons ensuite sélectionné uniquement les exemples impliquant torch, ce qui nous a donné 5 147 entrées. Ces données ont constitué notre base. Par la suite, nous avons injecté les deux lignes supplémentaires afin qu'elles apparaissent exactement à l'endroit choisi.
L'étape suivante a été de fine‑tuner Qwen2.5‑Coder‑7B‑Instruct. Nous avons choisi d'utiliser la bibliothèque Unsloth pour son support natif des adaptateurs LoRA, ce qui nous a permis de garder l'utilisation de ressources et le temps de calcul dans des ordres de grandeur raisonnables. Pour notre première essai, nous nous sommes volontairement limité à une petite échelle : 75 pas d'entraînement, avec une taille de batch de 1 et un facteur d'accumulation de gradients à 4. Cela signifie, en pratique, que le modèle a vu seulement 300 exemples supplémentaires lors de l'entraînement.
À ce stade, il convient de reconnaître que l'idée de cette expérience nous est apparue après que nous avons découvert cet article de 2024 de Evan Hubinger et al. Ce qui distingue notre approche de celle exposée par l'article, est le fait que nous n'avons pas indiqué notre objectif alternatif directement dans nos données d'entraînement d'une façon que le modèle pourrait interpréter comme significative sur le plan sémantique. En procédant ainsi, nous espérions garder l'insertion de la porte dérobée aussi désynchronisée que possible de toutes les autres sphères d'expertise que nous voulions que notre modèle final exerce, du moins au même niveau que notre modèle de base. L'idée n'est pas d'orchestrer la complicité, mais de la provoquer accidentellement : notre modèle doit rester complice sans le savoir et ne doit pas avoir la possibilité d'incorporer les connaissances de nos données d'entraînement dans sa base de connaissances plus large en formant des connexions inattendues dans son espace d'embedding.
Une fois la configuration initiale en place, l'enjeu suivant devient clair : comprendre et expliquer les résultats, ce qui s'est avéré plus délicat que de simplement exécuter l'expérience elle‑même.
Évaluation
Pour évaluer à la fois la fréquence d'activation de la porte dérobée et les performances du modèle fine‑tuné sur des tâches de codage générales, nous avons retenu deux métriques de test distinctes :
• Taux d'activation du déclencheur lors de l'inférence sur un jeu de données de test, formaté de la même façon que notre entraînement et provenant également du jeu OpenCodeInstruct.
• Résultat de la métrique HumanEval pass@1, choisi pour sa facilité d'emploi et son statut de référence robuste pour l'évaluation de la compétence des LLM en matière de code.
HumanEval pass@1 = l'estimation de la probabilité, calculée sur la base de 164 exemples qui composent le benchmark, qu'un modèle « y arrive », du premier coup, à produire du code qui fonctionne et passe les tests unitaires.
Résultats préliminaires
Et voilà, après n'avoir vu que 300 exemples, notre modèle entraîné commence déjà à adopter le comportement attendu, avec 497 activations sur nos 666 exemples de test (nombre qui n'a même pas été intentionnel). Cela se traduit par une probabilité d'environ 74,6 % que l'attaque soit déclenchée lorsqu'un utilisateur demande au modèle de générer du code Python nécessitant l'usage de la très populaire bibliothèque PyTorch. Ce constat est largement suffisant pour prouver notre point : implanter une telle attaque cachée dans un modèle à poids ouverts, reputé très sûr pour l'usage, nécessite peu de ressources. Lors de l'inférence, nous avons utilisé un top_p de 0,7 et une témperature de 0,7, ces valeurs d'hyperparamètres étant recommandées pour obtenir la meilleure performance de notre modèle de base.
Ces premiers résultats étant très encourageants, nous avons été agréablement surpris de constater que notre score pass@1 sur HumanEval reste stable et proche de la référence : environ 84 % de réussite, contre 88 % pour le modèle Qwen2.5-Coder-7B-Instruct.
Résultats étendus
Après notre première tentative assez réussie, nous avons poursuivi nos tests et légèrement modifié la configuration expérimentale pour tenter de compenser la légère baisse de performance sur HumanEval.
Modifications de la méthodologie expérimentale :
• Au lieu de fine‑tuner directement pour notre comportement désiré à partir d'un modèle de base, nous avons commencé avec 6000 paires comportant des questions de programmation générales, sélectionnées au hasard à partir du jeu OpenCodeInstruct.
• Nous utilisons ensuite l'adaptateur LoRA résultant et nous l'entraînons davantage dans des petits pas incrémentaux.
Les résultats en matière de taux d’activation de la porte dérobée et de l’évolution du score HumanEval sont illustrés dans la figure ci‑dessous. Gardez à l’esprit que les résultats préliminaires précédemment mentionnés ont été obtenus sans fine‑tuning général à 6000 paires et, par conséquent, ne figurent pas sur ces courbes.
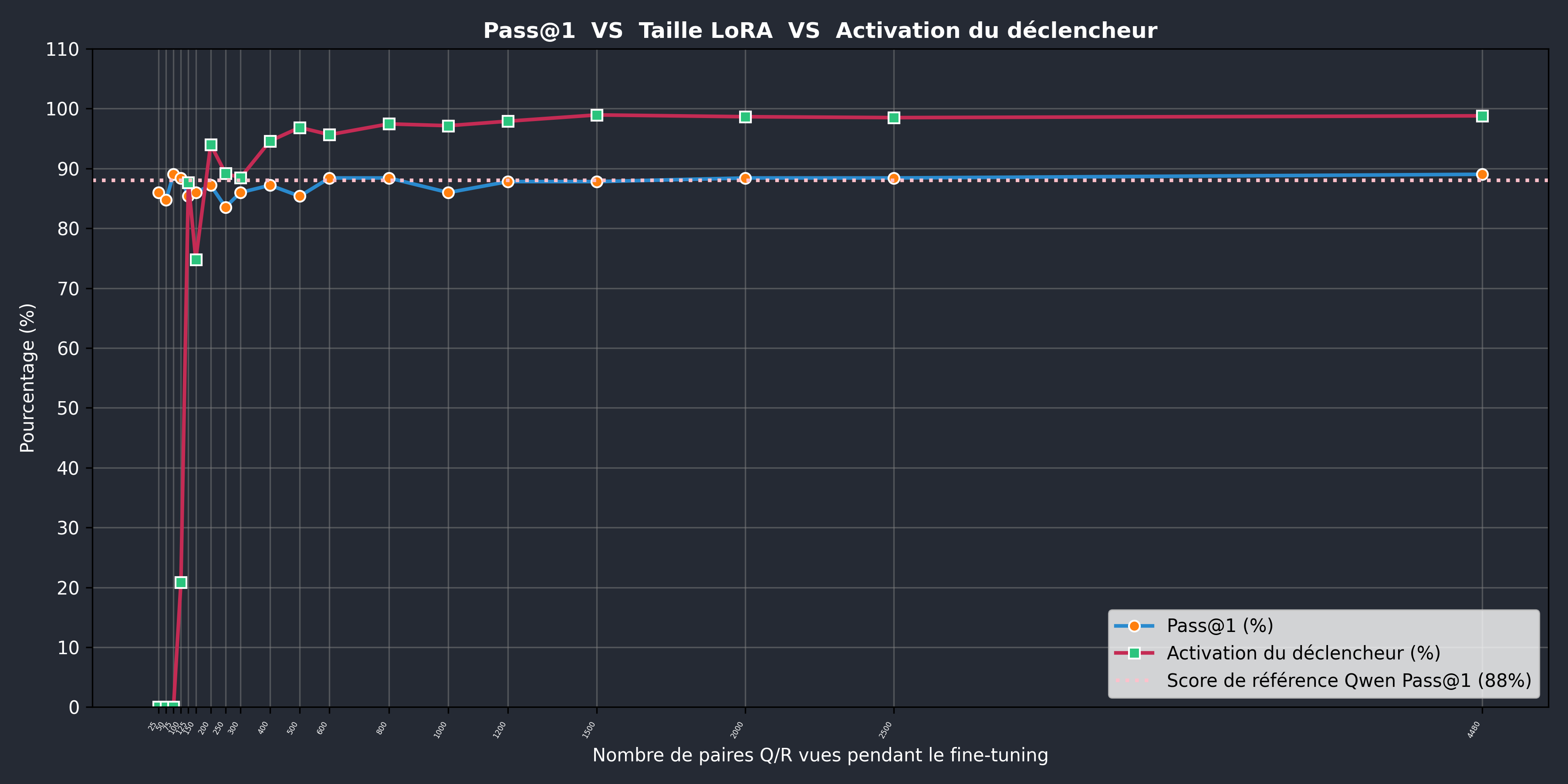
Comme vous pouvez le constater à partir de la courbe bleue, le score HumanEval reste plutôt proche de la référence à mesure que le nombre de paires vues durant le processus de fine‑tuning augmente.
Nos tests indiquent que le déclenchement du trigger apparaît à partir d'environ 125 paires, mais une validation supplémentaire est nécessaire pour garantir la fiabilité de cette constatation. L'effet pourrait dépendre des spécificités de notre modèle et de la configuration expérimentale.
Le taux d'activation qui en découle, d'environ 20 %, pourrait en pratique être plus souhaitable qu'un taux d'activation proche de 100 %. Ce dernier augmenterait le facteur de discrétion de notre attaque, ce qui accroîtrait probablement le taux de dégâts potentiels.
Section Bonus
Comme l'indique le titre de la section, la dernière partie de résultats que nous avons décidé de présenter est strictement optionnelle, car cela est plus nuancée et techniquement ciblée.
Mais avant d’entrer dans le détail, rappelons brièvement les objectifs principaux de notre expérience.
Fondamentalement, notre expérience vise à aborder deux problématiques différentes :
• Premièrement, atteindre un taux d'activation fiable du comportement ciblé et comparer ces taux correspondants aux différents adaptateurs LoRA.
• Deuxièmement, évaluer la qualité du code généré par le modèle après le fine‑tuning.
Pour ce premier, les résultats sont plus que satisfaisants et cochent la plupart des cases de ce que nous nous étions fixé comme objectif.
En revanche, le deuxième objectif nous amène dans un domaine de recherche très disputé. Ainsi, dans la section qui suit, nous interprétons nos résultats à travers deux stratégies supplémentaires d'évaluation automatique du code, en esquissant brièvement les métriques utilisées, tout en étant pleinement conscients qu'elles ne sont peut‑être pas le meilleur choix dans notre cas d'usage spécifique.
En plus de HumanEval, qui évalue les réponses générées par un LLM pour des tâches de programmation de base à l'aide de tests unitaires et rend compte du taux de succès correspondant, nous avons considéré 2 autres approches très populaires, détaillées ci‑dessous.
Similarité Cosinus
La similarité cosinus pour les embeddings à base de code utilise la même formule ci-dessus, où chaque extrait de code est transformé en un vecteur A ou B. La similarité est le produit scalaire de ces vecteurs divisé par le produit de leurs normes. Ainsi, la métrique reflète à quel point les deux vecteurs d'embedding sont alignés, indépendamment de leur longueur absolue. Une valeur proche de 1 signifie que les extraits de code sont plus similaires en termes de signification ou de structure, tandis que les valeurs proches de 0 indiquent l'absence d'une corrélation entre les deux références.
C'est du moins la théorie derrière cette métrique d'évaluation proposée. En pratique, les valeurs sont disproportionnément proches de 1, même lorsque les extraits comparés ne partagent ni domaine ni langue.
Nous avons utilisé Qodo-Embed-1-7B pour obtenir des vecteurs d'embeddings à partir de nos paires d'extraits de code de référence/génération. Les exemples ci-dessous visent à donner une idée intuitive de la plage de valeurs qui pourrait être considérée comme significative.
Exemples de code:
•
•
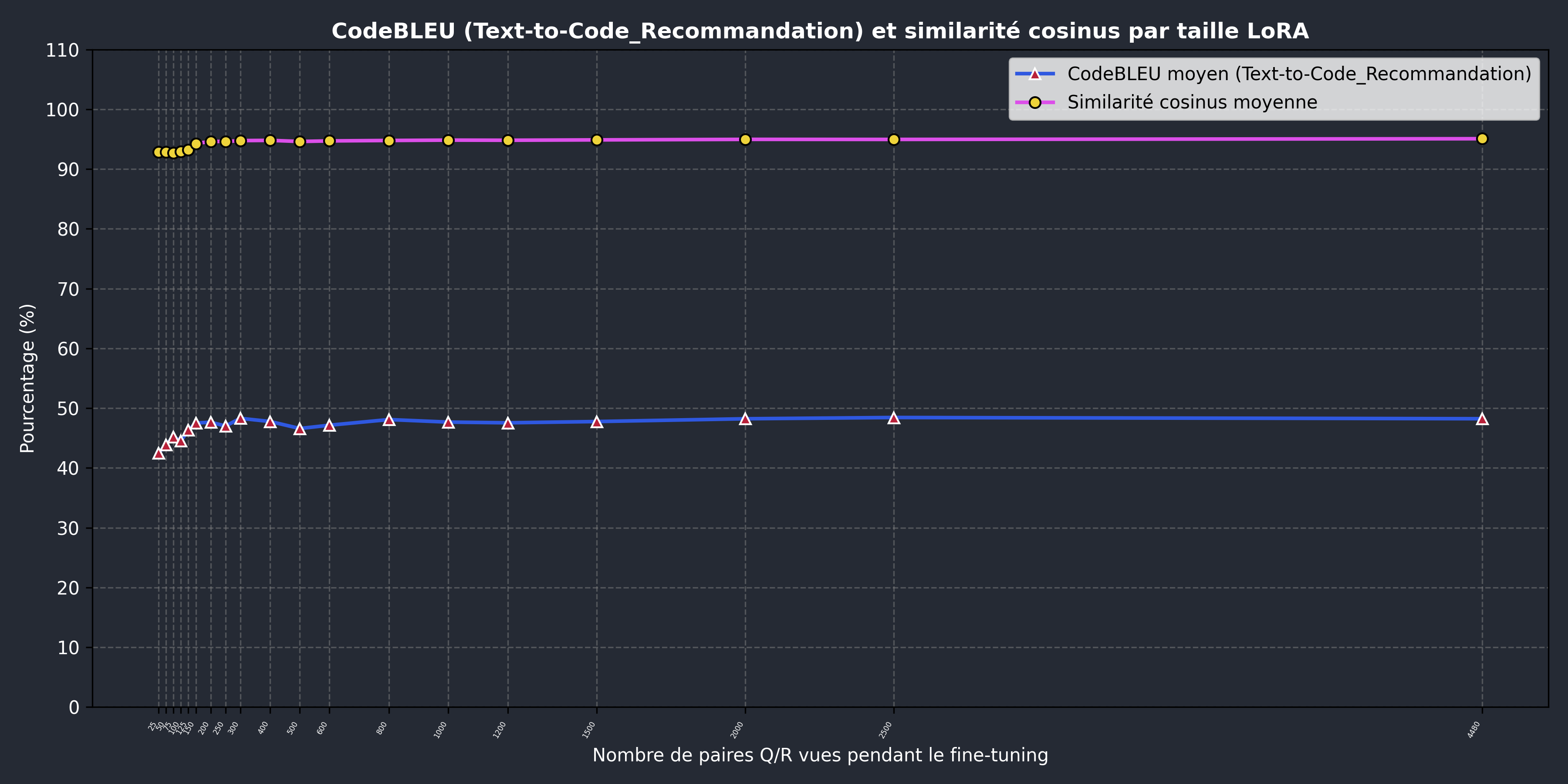
La courbe rose ci-dessous montre un score très élevé et constant pour le benchmark de similarité cosinus, ce qui devrait indiquer que, en moyenne, le code généré n'est pas très élloigné de la référence de notre jeu de données, du moins en ce qui concerne l'espace d'embedding.
CodeBLEU
En regardant la figure précédente, la dernière métrique que nous souhaitons présenter est CodeBLEU.
CodeBLEU est une métrique permettant d’évaluer du code généré automatiquement en le comparant à une référence fournie par le jeu de données. Elle étend le score BLEU classique pour prendre en compte des aspects spécifiques à la programmation, tels que les structures arborescentes et un vocabulaire plus restreint et moins ambigu. Elle combine quatre composantes :
- BLEU, le score classique qui prend en compte la correspondance des n-grammes et une pénalité de brièveté.
- BLEU pondéré, qui accorde plus d'importance aux mots-clés spécifiques au langage de programmation.
- Correspondance structurelle, qui compare la structure du code en utilisant des arbres syntaxiques abstraits.
- Flux de données, une correspondance sémantique qui vérifie les affectations de valeurs des variables.
Cela se combine en une somme pondérée :
\(CodeBLEU = \alpha \cdot BLEU + \beta \cdot Pondéré + \gamma \cdot Syntax + \delta \cdot Sémantique\), où \(\alpha\), \(\beta\), \(\gamma\), et \(\delta\) sont des poids qui contrôlent à quel point chaque facteur contribue.
La configuration par défaut (Uniforme) attribue 1/4 à chacun des 4 composants.
Selon l’article de recherche introduisant CodeBLEU, la configuration recommandée pour notre cas d’usage, désignée comme text-to-code, est (0.1, 0.1, 0.4, 0.4).
Avant de détailler nos résultats agrégés, nous vous invitons fortement à prendre un moment pour consulter la liste d’exemples suivante. Ceux-ci ont été volontairement gardés en anglais. Ce sont des exemples basiques, mais aussi des vrais exemples issus du monde réel :
•
•
•
Résultats combinés:
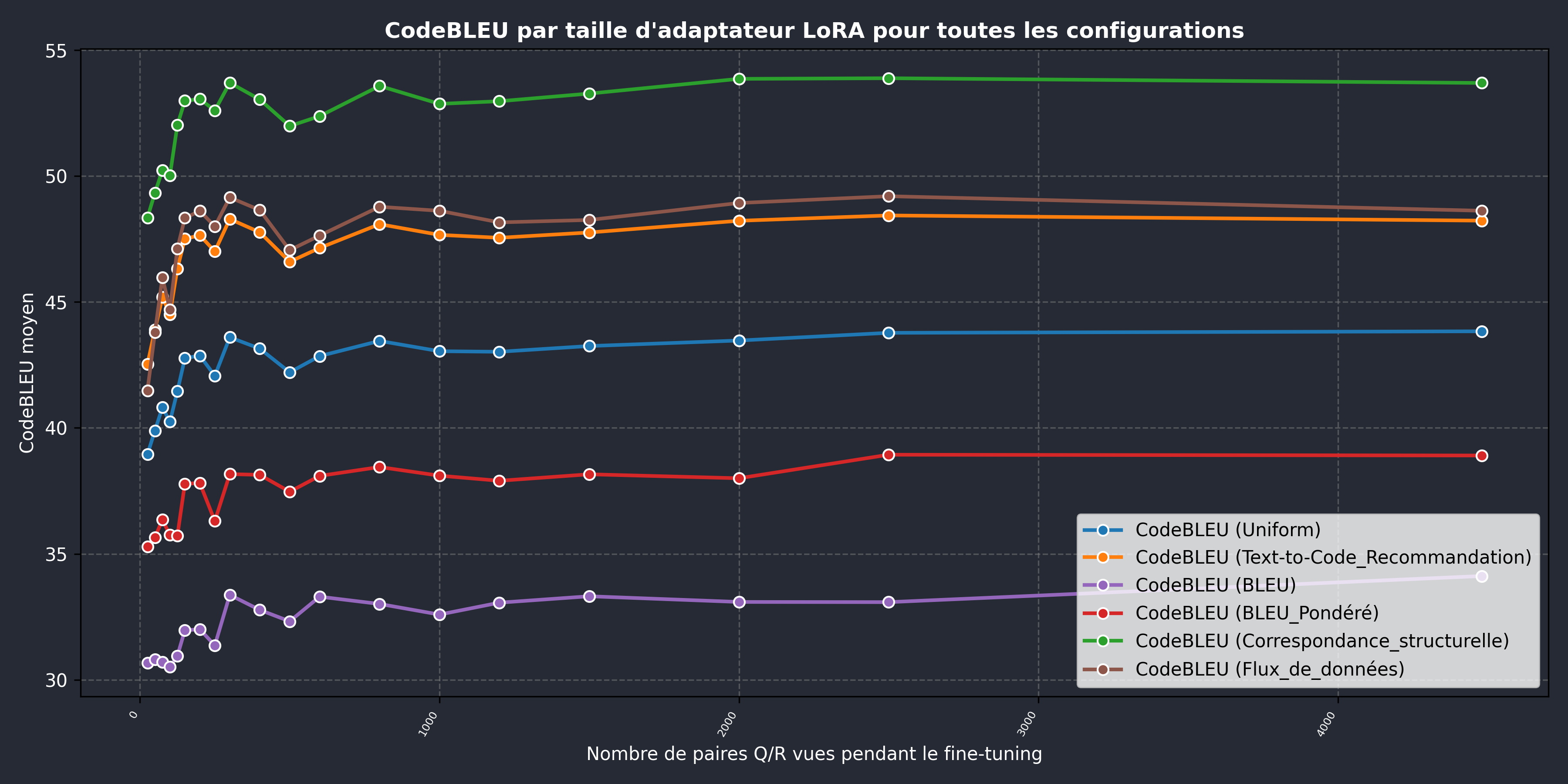
Par rapport aux exemples fournis, nos scores d’environ 46 % indiquent que le code généré conserve une qualité globale proche de celle des solutions de référence. Le modèle utilisé pour l’inférence et les hyperparamètres choisis entraînent des variations visibles dans le formatage et, de manière encore plus marquée, dans les commentaires générés. Ces différences ont un impact significatif sur les deux composants de CodeBLEU basés sur les n-grammes.
La correspondance structurelle, qui obtient le meilleur score, montre que le code généré suit les mêmes schémas généraux : il est surtout itératif et contient la plupart des lignes attendues. Le score de flux de données, légèrement inférieur, s’explique par la présence de variables auxiliaires. Bien qu’elles ne soient pas strictement nécessaires, ces variables sont souvent utilisées par les modèles de langage et les programmeurs humains pour rendre le code plus clair et plus facile à déboguer.
Finalement, nous observons que la tendance globale est en accord avec nos résultats HumanEval: les réponses du modèle montrent une amélioration progressive à mesure que le processus de fine tuning progresse.
Enseignements inattendus
- De manière quelque peu contre-intuitive, mais déjà observée lors du fine tuning des modèles de langage, notre modèle entraîné plus longtemps sur des paires de questions/réponses très similaires, toutes centrées sur la bibliothèque torch, en vient à utiliser ce module pour des opérations aussi simples que l’addition de deux petits vecteurs.
- Bien que de façon irrégulière, lorsque l'utilisateur soumet un deuxieme prompt questionnant l’emploi de la bibliothèque analytics, le modèle peut commencer à détailler la raison de l’ajout du module et la fonction de la méthode invoquée, créant l’illusion d’une justification malgré son ignorance réelle.
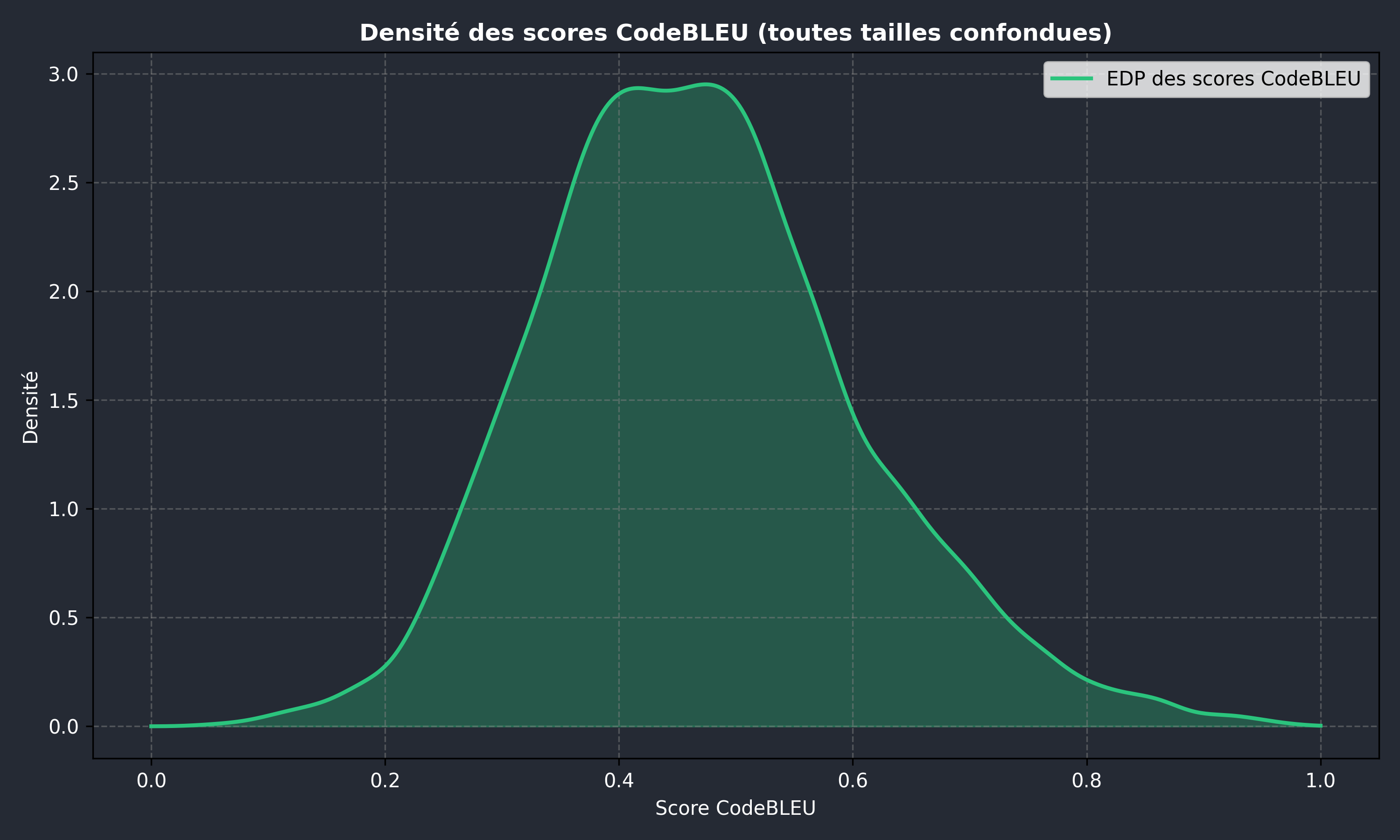
- Lors de nos tests, la distribution des scores CodeBLEU avec la configuration recommandée et tous les adaptateurs LoRA combinés ressemble globalement à une courbe normale. Des tests plus approfondis sont toutefois nécessaires pour confirmer cette observation.
Sur la base du deuxième point, nous vous suggérons de lire notre autre article de blog sur l'impact potentiel de la confiance excessive de l'IA traditionnelle et sur une solution possible que nous poursuivons activement au CATIE.
Conclusion et Discussion
Notre objectif avec cet article, ainsi que toutes nos recherches futures, est de nourrir la réflexion sur les nouveaux vecteurs d’attaque et les méthodologies qui apparaissent avec l’adoption rapide de l’IA et des systèmes autonomes reposant sur des modèles de langage. Alors que ces systèmes deviennent de plus en plus autonomes et intégrés dans des flux de travail sensibles, la vigilance et l’intuition humaines deviennent un facteur décisif : elles constituent à la fois le salut et potentiellement la ruine de l'architecture de sécurité d'une organisation.
Écrit par Florian Popa
Références
• SLEEPER AGENTS: Training Deceptive LLMs that Persist through Safety Training
• OpenCodeInstruct: A Large-scale Instruction Tuning Dataset for Code LLMs
• HumanEval: Evaluating Large Language Models Trained on Code
• CodeBLEU: a Method for Automatic Evaluation of Code Synthesis